Naive_Bayes를 이용한 리뷰 분류 -colab
YELP 서비스의 리뷰 분석 (NLP)
PROBLEM STATEMENT
- stars 컬럼은, 유저가 1점부터 5점까지 준 별점이 들어있다.
- text 컬럼은, 별점을 준 유저의 리뷰가 들어있다.
- cool, useful, funny 컬럼은, 다른사람들이 이 리뷰 글에 투표한 숫자다. 따라서 쿨이 3개이면, 이 리뷰에 대해서 3명이 쿨에 공감했다는 뜻이다.
STEP #0: LIBRARIES IMPORT
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
import os
os.chdir('/content/drive/MyDrive/python/day15')
STEP #1: IMPORT DATASET
yelp.csv 파일을 읽어서, yelp_df 변수에 저장하고, 기본적인 통계 분석을 하시오.
df = pd.read_csv('yelp.csv')
df.head(5)
| business_id | date | review_id | stars | text | type | user_id | cool | useful | funny | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9yKzy9PApeiPPOUJEtnvkg | 2011-01-26 | fWKvX83p0-ka4JS3dc6E5A | 5 | My wife took me here on my birthday for breakf... | review | rLtl8ZkDX5vH5nAx9C3q5Q | 2 | 5 | 0 |
| 1 | ZRJwVLyzEJq1VAihDhYiow | 2011-07-27 | IjZ33sJrzXqU-0X6U8NwyA | 5 | I have no idea why some people give bad review... | review | 0a2KyEL0d3Yb1V6aivbIuQ | 0 | 0 | 0 |
| 2 | 6oRAC4uyJCsJl1X0WZpVSA | 2012-06-14 | IESLBzqUCLdSzSqm0eCSxQ | 4 | love the gyro plate. Rice is so good and I als... | review | 0hT2KtfLiobPvh6cDC8JQg | 0 | 1 | 0 |
| 3 | _1QQZuf4zZOyFCvXc0o6Vg | 2010-05-27 | G-WvGaISbqqaMHlNnByodA | 5 | Rosie, Dakota, and I LOVE Chaparral Dog Park!!... | review | uZetl9T0NcROGOyFfughhg | 1 | 2 | 0 |
| 4 | 6ozycU1RpktNG2-1BroVtw | 2012-01-05 | 1uJFq2r5QfJG_6ExMRCaGw | 5 | General Manager Scott Petello is a good egg!!!... | review | vYmM4KTsC8ZfQBg-j5MWkw | 0 | 0 | 0 |
STEP #2: VISUALIZE DATASET
리뷰 데이터의 길이를 구하여, 새로운 컬럼 length 컬럼을 만드시오
df['length']= df['text'].apply(len)
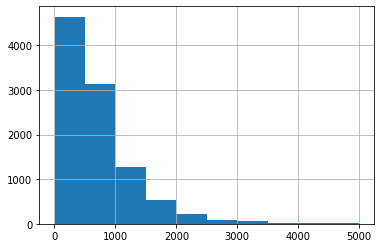
리뷰의 length를 히스토그램으로 나타내시오.
df['length'].hist()
plt.show()
리뷰가 가장 긴 글을 찾아서, 리뷰 내용을 보여주세요.
(df.loc[df['length'] == df['length'].max(),])['text'].values
리뷰가 가장 짧은 리뷰는 총 몇개이며, 리뷰 내용은 무엇입니까?
(df.loc[df['length'] == df['length'].min(),])['text'].values
array(['X'], dtype=object)
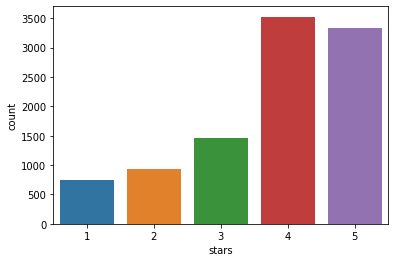
별점은 1점부터 5점까지 입니다. 각 별점별로 리뷰가 몇개씩 있는지를 시각화 하시오.
sns.countplot(data = df,x='stars')
plt.show()
별점별로 리뷰가 몇개씩 있는지 시각화 하되, 내림차순으로 정렬하여 시각화 하시오.
my_order = df['stars'].value_counts().index
sns.countplot(data = df,x='stars',order=my_order)
plt.show()
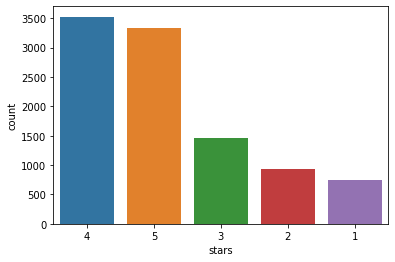
별점이 1점인 리뷰의 데이터프레임과, 별점아 5점인 데이터프레임을 각각 따로 아래의 변수에 저장하시오. 변수명은 yelp_df_1 , yelp_df_5 로 저장하시오.
yelp_df_1 = df.loc[df['stars'] == 1,]
yelp_df_5 = df.loc[df['stars'] == 5,]
yelp_df_1 , yelp_df_5 두개의 데이터프레임을 하나로 합치시오. 긍정과 부정의 리뷰 학습을 위해서 하나로 합치는 것이다.
yelp_df_1_5 = pd.concat([yelp_df_1,yelp_df_5])
yelp_df_1_5
| business_id | date | review_id | stars | text | type | user_id | cool | useful | funny | length | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 23 | IJ0o6b8bJFAbG6MjGfBebQ | 2010-09-05 | Dx9sfFU6Zn0GYOckijom-g | 1 | U can go there n check the car out. If u wanna... | review | zRlQEDYd_HKp0VS3hnAffA | 0 | 1 | 1 | 594 |
| 31 | vvA3fbps4F9nGlAEYKk_sA | 2012-05-04 | S9OVpXat8k5YwWCn6FAgXg | 1 | Disgusting! Had a Groupon so my daughter and ... | review | 8AMn6644NmBf96xGO3w6OA | 0 | 1 | 0 | 361 |
| 35 | o1GIYYZJjM6nM03fQs_uEQ | 2011-11-30 | ApKbwpYJdnhhgP4NbjQw2Q | 1 | I've eaten here many times, but none as bad as... | review | iwUN95LIaEr75TZE_JC6bg | 0 | 4 | 3 | 1198 |
| 61 | l4vBbCL9QbGiwLuLKwD_bA | 2011-11-22 | DJVxOfj2Rw9zklC9tU3i1w | 1 | I have always been a fan of Burlington's deals... | review | EPROVap0M19Y6_4uf3eCmQ | 0 | 0 | 0 | 569 |
| 64 | CEswyP-9SsXRNLR9fFGKKw | 2012-05-19 | GXj4PNAi095-q9ynPYH3kg | 1 | Another night meeting friends here. I have to... | review | MjLAe48XNfYlTeFYca5gMw | 0 | 1 | 2 | 498 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9990 | R8VwdLyvsp9iybNqRvm94g | 2011-10-03 | pcEeHdAJPoFNF23es0kKWg | 5 | Yes I do rock the hipster joints. I dig this ... | review | b92Y3tyWTQQZ5FLifex62Q | 1 | 1 | 1 | 263 |
| 9991 | WJ5mq4EiWYAA4Vif0xDfdg | 2011-12-05 | EuHX-39FR7tyyG1ElvN1Jw | 5 | Only 4 stars? \n\n(A few notes: The folks that... | review | hTau-iNZFwoNsPCaiIUTEA | 1 | 1 | 0 | 908 |
| 9992 | f96lWMIAUhYIYy9gOktivQ | 2009-03-10 | YF17z7HWlMj6aezZc-pVEw | 5 | I'm not normally one to jump at reviewing a ch... | review | W_QXYA7A0IhMrvbckz7eVg | 2 | 3 | 2 | 1326 |
| 9994 | L3BSpFvxcNf3T_teitgt6A | 2012-03-19 | 0nxb1gIGFgk3WbC5zwhKZg | 5 | Let's see...what is there NOT to like about Su... | review | OzOZv-Knlw3oz9K5Kh5S6A | 1 | 2 | 1 | 1968 |
| 9999 | pF7uRzygyZsltbmVpjIyvw | 2010-10-16 | vWSmOhg2ID1MNZHaWapGbA | 5 | 4-5 locations.. all 4.5 star average.. I think... | review | KSBFytcdjPKZgXKQnYQdkA | 0 | 0 | 0 | 461 |
4086 rows × 11 columns
별점 1과 별점 5의 리뷰는 몇개씩인지, 시각화 하시오.
sns.countplot(data=yelp_df_1_5,x='stars')
plt.show()
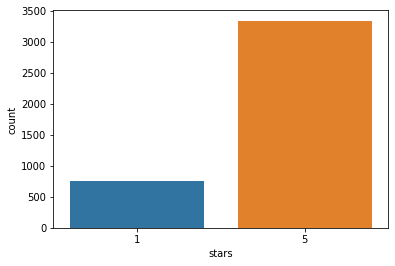
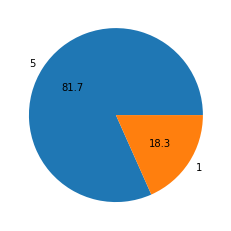
별점 1점과 별점 5점의 리뷰의 비율이 나오도록, 파이차트로 시각화 하시오.
yelp_df_1_5['stars'].value_counts()
5 3337
1 749
Name: stars, dtype: int64
plt.pie(yelp_df_1_5['stars'].value_counts(),labels=yelp_df_1_5['stars'].value_counts().index,autopct='%.1f')
plt.show()
STEP #3: CREATE TESTING AND TRAINING DATASET/DATA CLEANING
정리 : 위의 과정을 하나의 함수로 만든다.
import string
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
my_stopwords = stopwords.words('english')
def message_cleaning(sentence) :
Test_punc_removed = [ char for char in sentence if char not in string.punctuation]
Test_punc_removed_join = ''.join(Test_punc_removed)
Test_punc_removed_join_clean = [word for word in Test_punc_removed_join.split() if word.lower() not in my_stopwords ]
return Test_punc_removed_join_clean
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
COUNT VECTORIZER 에 클리닝 함수를 애널라이저로 적용하여, 단어를 숫자로 바꾼다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer=message_cleaning)
X = vectorizer.fit_transform(yelp_df_1_5['text'])
X = X.toarray()
y = yelp_df_1_5['stars']
STEP#4: 학습용과 테스트용으로 데이터프레임을 나눈다. 테스트용은 20%로 설정한다. 그리고 나이브베이즈 모델링 한다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2 , random_state=15)
from sklearn.naive_bayes import MultinomialNB, GaussianNB
classirier1 = MultinomialNB()
classirier1.fit(X_train,y_train)
MultinomialNB()
y_pred = classirier1.predict(X_test)
classirier2 = GaussianNB()
classirier2.fit(X_train,y_train)
GaussianNB()
y_pred_G = classirier2.predict(X_test)
STEP#5: 테스트셋으로 모델 평가. 컨퓨전 매트릭스 사용한다.
from sklearn.metrics import confusion_matrix, accuracy_score
confusion_matrix(y_test,y_pred)
array([[111, 52],
[ 17, 638]])
accuracy_score(y_test,y_pred)
0.9156479217603912
confusion_matrix(y_test,y_pred_G)
array([[ 54, 109],
[ 82, 573]])
accuracy_score(y_test,y_pred_G)
0.7665036674816625
STEP#6 다음 문장이 긍정인지 부정인지 예측하시오.
- ‘amazing food! highly recommmended’
- ‘shit food, made me sick’
test = vectorizer.transform([ 'amazing food! highly recommmended','shit food, made me sick'])
test = test.toarray()
classirier1.predict(test)
array([5, 1])
댓글남기기