Linear_regression 실습
예측 모델 실습
auto-mpg.csv 데이터를 통해, mpg (mile per gallern, 자동차 연비) 를 예측하는 모델을 만드세요.
컬럼 정보 :
MPG (miles per gallon),
cylinders,
engine displacement (cu. inches),
horsepower,
vehicle weight (lbs.),
time to accelerate from O to 60 mph (sec.),
model year (modulo 100),
origin of car (1. American, 2. European,3. Japanese).
Also provided are the car labels (types)
Missing data values are marked by series of question marks.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('auto-mpg.csv')
df
| mpg | cyl | displ | hp | weight | accel | yr | origin | name | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | 1 | chevrolet chevelle malibu |
| 1 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | 1 | buick skylark 320 |
| 2 | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | 1 | plymouth satellite |
| 3 | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | 1 | amc rebel sst |
| 4 | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | 1 | ford torino |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 387 | 27.0 | 4 | 140.0 | 86 | 2790 | 15.6 | 82 | 1 | ford mustang gl |
| 388 | 44.0 | 4 | 97.0 | 52 | 2130 | 24.6 | 82 | 2 | vw pickup |
| 389 | 32.0 | 4 | 135.0 | 84 | 2295 | 11.6 | 82 | 1 | dodge rampage |
| 390 | 28.0 | 4 | 120.0 | 79 | 2625 | 18.6 | 82 | 1 | ford ranger |
| 391 | 31.0 | 4 | 119.0 | 82 | 2720 | 19.4 | 82 | 1 | chevy s-10 |
392 rows × 9 columns
df.drop('name',axis=1,inplace=True)
# 데이터에 Nan 값 찾기.
df.isna().sum()
mpg 0
cyl 0
displ 0
hp 0
weight 0
accel 0
yr 0
origin 0
dtype: int64
# 데이터 X와 y로 나누기
df.head()
| mpg | cyl | displ | hp | weight | accel | yr | origin | |
|---|---|---|---|---|---|---|---|---|
| 0 | 18.0 | 8 | 307.0 | 130 | 3504 | 12.0 | 70 | 1 |
| 1 | 15.0 | 8 | 350.0 | 165 | 3693 | 11.5 | 70 | 1 |
| 2 | 18.0 | 8 | 318.0 | 150 | 3436 | 11.0 | 70 | 1 |
| 3 | 16.0 | 8 | 304.0 | 150 | 3433 | 12.0 | 70 | 1 |
| 4 | 17.0 | 8 | 302.0 | 140 | 3449 | 10.5 | 70 | 1 |
X = df.iloc[:,1:]
y = df['mpg']
# origin 은 카테고리컬 데이터이므로 갯수 확인 후 원핫 인코딩.
sorted(X['origin'].unique())
[1, 2, 3]
X = pd.get_dummies(X,columns=['origin'])
# 학습용과 테스트 용으로 분리
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state=10)
## 리니어 리그레이션으로 모델링
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
# 인공지능 학습
regressor.fit(X_train,y_train)
LinearRegression()
# 인공지능 테스트
y_pred = regressor.predict(X_test)
error = y_test - y_pred
# MSE 구하기
(error**2).mean()
12.782792965646852
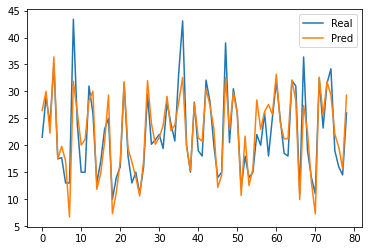
# 차트로 그리기
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real','Pred'])
plt.show()
# 방정식의 계수
regressor.coef_
array([-0.83960353, 0.03032018, -0.03061675, -0.00644172, 0.00434557,
0.75847227, -1.83056491, 0.54183524, 1.28872967])
# 방정식의 상수항
regressor.intercept_
-12.3134923524076
댓글남기기