Hierar
Cust_Spend_Data.csv 파일을 통해서 고객의 의류소비, 음료소비, 음식소비 대이터를 통해서 비슷한 고객으로 그루핑 하자
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
df = pd.read_csv('Cust_Spend_Data.csv')
|
Cust_ID |
Name |
Avg_Mthly_Spend |
No_Of_Visits |
Apparel_Items |
FnV_Items |
Staples_Items |
| 0 |
1 |
A |
10000 |
2 |
1 |
1 |
0 |
| 1 |
2 |
B |
7000 |
3 |
0 |
10 |
9 |
| 2 |
3 |
C |
7000 |
7 |
1 |
3 |
4 |
| 3 |
4 |
D |
6500 |
5 |
1 |
1 |
4 |
| 4 |
5 |
E |
6000 |
6 |
0 |
12 |
3 |
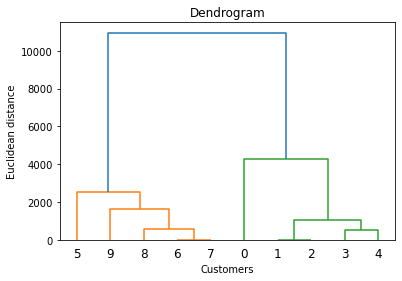
import scipy.cluster.hierarchy as sch
sch.dendrogram(sch.linkage(X,method='ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distance')
plt.show()
from sklearn.cluster import AgglomerativeClustering
# 덴드로그램에서 가장 적절한 기준으로 그룹을 묶는다면 3개의 그룹이 적당할거 같다.
hc = AgglomerativeClustering(n_clusters=3)
y_pred = hc.fit_predict(X)
|
Cust_ID |
Name |
Avg_Mthly_Spend |
No_Of_Visits |
Apparel_Items |
FnV_Items |
Staples_Items |
Gruop |
| 0 |
1 |
A |
10000 |
2 |
1 |
1 |
0 |
2 |
| 1 |
2 |
B |
7000 |
3 |
0 |
10 |
9 |
1 |
| 2 |
3 |
C |
7000 |
7 |
1 |
3 |
4 |
1 |
| 3 |
4 |
D |
6500 |
5 |
1 |
1 |
4 |
1 |
| 4 |
5 |
E |
6000 |
6 |
0 |
12 |
3 |
1 |
| 5 |
6 |
F |
4000 |
3 |
0 |
1 |
8 |
0 |
| 6 |
7 |
G |
2500 |
5 |
0 |
11 |
2 |
0 |
| 7 |
8 |
H |
2500 |
3 |
0 |
1 |
1 |
0 |
| 8 |
9 |
I |
2000 |
2 |
0 |
2 |
2 |
0 |
| 9 |
10 |
J |
1000 |
4 |
0 |
1 |
7 |
0 |
sb.pairplot(data=X)
plt.show()
|
Cust_ID |
Avg_Mthly_Spend |
No_Of_Visits |
Apparel_Items |
FnV_Items |
Staples_Items |
Gruop |
| Cust_ID |
1.000000 |
-0.972438 |
-0.129550 |
-0.645777 |
-0.183822 |
-0.012012 |
-0.892269 |
| Avg_Mthly_Spend |
-0.972438 |
1.000000 |
0.102229 |
0.715422 |
0.081890 |
-0.107431 |
0.960886 |
| No_Of_Visits |
-0.129550 |
0.102229 |
1.000000 |
0.270666 |
0.376214 |
0.042796 |
0.093495 |
| Apparel_Items |
-0.645777 |
0.715422 |
0.270666 |
1.000000 |
-0.387325 |
-0.301169 |
0.723747 |
| FnV_Items |
-0.183822 |
0.081890 |
0.376214 |
-0.387325 |
1.000000 |
0.093025 |
0.074517 |
| Staples_Items |
-0.012012 |
-0.107431 |
0.042796 |
-0.301169 |
0.093025 |
1.000000 |
-0.208063 |
| Gruop |
-0.892269 |
0.960886 |
0.093495 |
0.723747 |
0.074517 |
-0.208063 |
1.000000 |
댓글남기기