Prophet을 이용한 범죄율 예측 -colab
시카고 범죄율을 예측해 보자 ( Facebook 의 Prophet 라이브러리 활용 )
STEP #0: PROBLEM STATEMENT
- The Chicago Crime dataset : 2001 ~ 2017.
- Datasource: 캐글 https://www.kaggle.com/currie32/crimes-in-chicago
- Dataset contains the following columns:
- ID: Unique identifier for the record.
- Case Number: The Chicago Police Department RD Number (Records Division Number), which is unique to the incident.
- Date: Date when the incident occurred.
- Block: address where the incident occurred
- IUCR: The Illinois Unifrom Crime Reporting code.
- Primary Type: The primary description of the IUCR code.
- Description: The secondary description of the IUCR code, a subcategory of the primary description.
- Location Description: Description of the location where the incident occurred.
- Arrest: Indicates whether an arrest was made.
- Domestic: Indicates whether the incident was domestic-related as defined by the Illinois Domestic Violence Act.
- Beat: Indicates the beat where the incident occurred. A beat is the smallest police geographic area – each beat has a dedicated police beat car.
- District: Indicates the police district where the incident occurred.
- Ward: The ward (City Council district) where the incident occurred.
- Community Area: Indicates the community area where the incident occurred. Chicago has 77 community areas.
- FBI Code: Indicates the crime classification as outlined in the FBI’s National Incident-Based Reporting System (NIBRS).
- X Coordinate: The x coordinate of the location where the incident occurred in State Plane Illinois East NAD 1983 projection.
- Y Coordinate: The y coordinate of the location where the incident occurred in State Plane Illinois East NAD 1983 projection.
- Year: Year the incident occurred.
- Updated On: Date and time the record was last updated.
- Latitude: The latitude of the location where the incident occurred. This location is shifted from the actual location for partial redaction but falls on the same block.
- Longitude: The longitude of the location where the incident occurred. This location is shifted from the actual location for partial redaction but falls on the same block.
- Location: The location where the incident occurred in a format that allows for creation of maps and other geographic operations on this data portal. This location is shifted from the actual location for partial redaction but falls on the same block.
페이스북에서 만든 오픈소스 Prophet 라이브러리
-
Seasonal time series data를 분석할 수 있는 딥러닝 라이브러리다.
-
프로펫 공식 레이지 : https://research.fb.com/prophet-forecasting-at-scale/ https://facebook.github.io/prophet/docs/quick_start.html#python-api
코랩에는 자동으로 prophet이 설치되어 있다. 따라서 다른 환경에서 설치 되어있지 않다면, 다음처럼 설치하면 된다.
-
pip install fbprophet
-
위의 pip 설치 시 에러가 나면 다음처럼 설치해 준다 : conda install -c conda-forge fbprophet
STEP #1: IMPORTING DATA
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
import seaborn as sns
from fbprophet import Prophet
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
import os
os.chdir('/content/drive/MyDrive/python/day15')
# Chicago_Crimes_2005_to_2007.csv
# Chicago_Crimes_2008_to_2011.csv
# Chicago_Crimes_2012_to_2017.csv 파일을 읽되,
# 각각 파라미터 error_bad_lines=False 추가 해준다.
# ParserError => error_bad_lines=Fasle를 통하여
# 이상한 데이터만 빼고 다 살릴수가 있다.
chicago_df_1 = pd.read_csv("Chicago_Crimes_2005_to_2007.csv",error_bad_lines=False,index_col=0)
chicago_df_2 = pd.read_csv("Chicago_Crimes_2008_to_2011.csv",error_bad_lines=False,index_col=0)
chicago_df_3 = pd.read_csv("Chicago_Crimes_2012_to_2017.csv",error_bad_lines=False,index_col=0)
b'Skipping line 533719: expected 23 fields, saw 24\n'
/usr/local/lib/python3.7/dist-packages/numpy/lib/arraysetops.py:580: FutureWarning:
elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
b'Skipping line 1149094: expected 23 fields, saw 41\n'
# 위의 3개 데이터프레임을 하나로 합친다.
chicago_df = pd.concat([chicago_df_1,chicago_df_2,chicago_df_3])
STEP #2: EXPLORING THE DATASET
# Let's view the head of the training dataset
chicago_df.head()
| ID | Case Number | Date | Block | IUCR | Primary Type | Description | Location Description | Arrest | Domestic | Beat | District | Ward | Community Area | FBI Code | X Coordinate | Y Coordinate | Year | Updated On | Latitude | Longitude | Location | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4673626 | HM274058 | 04/02/2006 01:00:00 PM | 055XX N MANGO AVE | 2825 | OTHER OFFENSE | HARASSMENT BY TELEPHONE | RESIDENCE | False | False | 1622 | 16.0 | 45.0 | 11.0 | 26 | 1136872.0 | 1936499.0 | 2006 | 04/15/2016 08:55:02 AM | 41.981913 | -87.771996 | (41.981912692, -87.771996382) |
| 1 | 4673627 | HM202199 | 02/26/2006 01:40:48 PM | 065XX S RHODES AVE | 2017 | NARCOTICS | MANU/DELIVER:CRACK | SIDEWALK | True | False | 321 | 3.0 | 20.0 | 42.0 | 18 | 1181027.0 | 1861693.0 | 2006 | 04/15/2016 08:55:02 AM | 41.775733 | -87.611920 | (41.775732538, -87.611919814) |
| 2 | 4673628 | HM113861 | 01/08/2006 11:16:00 PM | 013XX E 69TH ST | 051A | ASSAULT | AGGRAVATED: HANDGUN | OTHER | False | False | 321 | 3.0 | 5.0 | 69.0 | 04A | 1186023.0 | 1859609.0 | 2006 | 04/15/2016 08:55:02 AM | 41.769897 | -87.593671 | (41.769897392, -87.593670899) |
| 4 | 4673629 | HM274049 | 04/05/2006 06:45:00 PM | 061XX W NEWPORT AVE | 0460 | BATTERY | SIMPLE | RESIDENCE | False | False | 1633 | 16.0 | 38.0 | 17.0 | 08B | 1134772.0 | 1922299.0 | 2006 | 04/15/2016 08:55:02 AM | 41.942984 | -87.780057 | (41.942984005, -87.780056951) |
| 5 | 4673630 | HM187120 | 02/17/2006 09:03:14 PM | 037XX W 60TH ST | 1811 | NARCOTICS | POSS: CANNABIS 30GMS OR LESS | ALLEY | True | False | 822 | 8.0 | 13.0 | 65.0 | 18 | 1152412.0 | 1864560.0 | 2006 | 04/15/2016 08:55:02 AM | 41.784211 | -87.716745 | (41.784210853, -87.71674491) |
# Let's view the last elements in the training dataset
chicago_df['Date']
0 04/02/2006 01:00:00 PM
1 02/26/2006 01:40:48 PM
2 01/08/2006 11:16:00 PM
4 04/05/2006 06:45:00 PM
5 02/17/2006 09:03:14 PM
...
6250330 05/03/2016 11:33:00 PM
6251089 05/03/2016 11:30:00 PM
6251349 05/03/2016 12:15:00 AM
6253257 05/03/2016 09:07:00 PM
6253474 05/03/2016 11:38:00 PM
Name: Date, Length: 6017767, dtype: object
비어있는 데이터가 얼마나 되는지 확인하시오.
chicago_df.isna().sum()
ID 0
Case Number 7
Date 0
Block 0
IUCR 0
Primary Type 0
Description 0
Location Description 1974
Arrest 0
Domestic 0
Beat 0
District 89
Ward 92
Community Area 1844
FBI Code 0
X Coordinate 74882
Y Coordinate 74882
Year 0
Updated On 0
Latitude 74882
Longitude 74882
Location 74882
dtype: int64
다음 컬럼들을 삭제하시오.
‘Case Number’, ‘Case Number’, ‘IUCR’, ‘X Coordinate’, ‘Y Coordinate’,’Updated On’,’Year’, ‘FBI Code’, ‘Beat’,’Ward’,’Community Area’, ‘Location’, ‘District’, ‘Latitude’ , ‘Longitude’
chicago_df.drop(['Case Number', 'Case Number', 'IUCR', 'X Coordinate', 'Y Coordinate','Updated On','Year', 'FBI Code', 'Beat','Ward','Community Area', 'Location', 'District', 'Latitude' , 'Longitude'],axis=1,inplace=True)
chicago_df.isna().sum()
ID 0
Date 0
Block 0
Primary Type 0
Description 0
Location Description 1974
Arrest 0
Domestic 0
dtype: int64
Date 컬럼을 보니, 날짜 형식으로 되어있다. 이를 파이썬이 이해할 수 있는 날짜로 바꿔서 다시 Date 컬럼에 저장하시오.
chicago_df['Date']= pd.to_datetime(chicago_df['Date'],format = '%m/%d/%Y %I:%M:%S %p')
chicago_df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 6017767 entries, 0 to 6253474
Data columns (total 8 columns):
# Column Dtype
--- ------ -----
0 ID int64
1 Date datetime64[ns]
2 Block object
3 Primary Type object
4 Description object
5 Location Description object
6 Arrest bool
7 Domestic bool
dtypes: bool(2), datetime64[ns](1), int64(1), object(4)
memory usage: 332.9+ MB
Date 컬럼을 인덱스로 만드시오.
# 그룹바이 함수로는 년단위,월단위,시단위 등 단위별로 데이터 통합을 할 수가 없다
# 따라서 먼저 Data 컬럼을 인덱스로 만들어 주면 , resample 함수를 통해서 위와 같은 일들을 할수가 있다.
chicago_df.index= pd.DatetimeIndex(chicago_df['Date'])
chicago_df
| ID | Date | Block | Primary Type | Description | Location Description | Arrest | Domestic | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2006-04-02 13:00:00 | 4673626 | 2006-04-02 13:00:00 | 055XX N MANGO AVE | OTHER OFFENSE | HARASSMENT BY TELEPHONE | RESIDENCE | False | False |
| 2006-02-26 13:40:48 | 4673627 | 2006-02-26 13:40:48 | 065XX S RHODES AVE | NARCOTICS | MANU/DELIVER:CRACK | SIDEWALK | True | False |
| 2006-01-08 23:16:00 | 4673628 | 2006-01-08 23:16:00 | 013XX E 69TH ST | ASSAULT | AGGRAVATED: HANDGUN | OTHER | False | False |
| 2006-04-05 18:45:00 | 4673629 | 2006-04-05 18:45:00 | 061XX W NEWPORT AVE | BATTERY | SIMPLE | RESIDENCE | False | False |
| 2006-02-17 21:03:14 | 4673630 | 2006-02-17 21:03:14 | 037XX W 60TH ST | NARCOTICS | POSS: CANNABIS 30GMS OR LESS | ALLEY | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2016-05-03 23:33:00 | 10508679 | 2016-05-03 23:33:00 | 026XX W 23RD PL | BATTERY | DOMESTIC BATTERY SIMPLE | APARTMENT | True | True |
| 2016-05-03 23:30:00 | 10508680 | 2016-05-03 23:30:00 | 073XX S HARVARD AVE | CRIMINAL DAMAGE | TO PROPERTY | APARTMENT | True | True |
| 2016-05-03 00:15:00 | 10508681 | 2016-05-03 00:15:00 | 024XX W 63RD ST | BATTERY | AGGRAVATED: HANDGUN | SIDEWALK | False | False |
| 2016-05-03 21:07:00 | 10508690 | 2016-05-03 21:07:00 | 082XX S EXCHANGE AVE | BATTERY | DOMESTIC BATTERY SIMPLE | SIDEWALK | False | True |
| 2016-05-03 23:38:00 | 10508692 | 2016-05-03 23:38:00 | 001XX E 75TH ST | OTHER OFFENSE | OTHER WEAPONS VIOLATION | PARKING LOT/GARAGE(NON.RESID.) | True | False |
6017767 rows × 8 columns
범죄 유형의 갯수를 세고, 가장 많은것부터 내림차순으로 보여주세요.
chicago_df['Primary Type'].value_counts()
THEFT 1245111
BATTERY 1079178
CRIMINAL DAMAGE 702702
NARCOTICS 674831
BURGLARY 369056
OTHER OFFENSE 368169
ASSAULT 360244
MOTOR VEHICLE THEFT 271624
ROBBERY 229467
DECEPTIVE PRACTICE 225180
CRIMINAL TRESPASS 171596
PROSTITUTION 60735
WEAPONS VIOLATION 60335
PUBLIC PEACE VIOLATION 48403
OFFENSE INVOLVING CHILDREN 40260
CRIM SEXUAL ASSAULT 22789
SEX OFFENSE 20172
GAMBLING 14755
INTERFERENCE WITH PUBLIC OFFICER 14009
LIQUOR LAW VIOLATION 12129
ARSON 9269
HOMICIDE 5879
KIDNAPPING 4734
INTIMIDATION 3324
STALKING 2866
OBSCENITY 422
PUBLIC INDECENCY 134
OTHER NARCOTIC VIOLATION 122
NON-CRIMINAL 96
CONCEALED CARRY LICENSE VIOLATION 90
NON - CRIMINAL 38
HUMAN TRAFFICKING 28
RITUALISM 16
NON-CRIMINAL (SUBJECT SPECIFIED) 4
Name: Primary Type, dtype: int64
상위 15개까지만 보여주세요.
chicago_df['Primary Type'].value_counts().head(15)
THEFT 1245111
BATTERY 1079178
CRIMINAL DAMAGE 702702
NARCOTICS 674831
BURGLARY 369056
OTHER OFFENSE 368169
ASSAULT 360244
MOTOR VEHICLE THEFT 271624
ROBBERY 229467
DECEPTIVE PRACTICE 225180
CRIMINAL TRESPASS 171596
PROSTITUTION 60735
WEAPONS VIOLATION 60335
PUBLIC PEACE VIOLATION 48403
OFFENSE INVOLVING CHILDREN 40260
Name: Primary Type, dtype: int64
primary_type = chicago_df['Primary Type'].value_counts().head(15).index
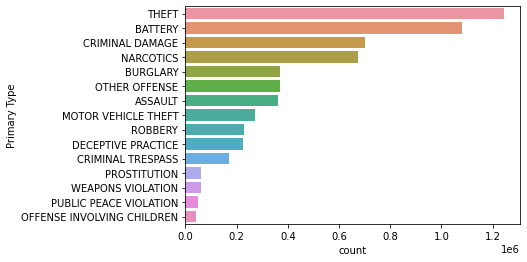
상위 15개의 범죄 유형(Primary Type)의 갯수를, 비주얼라리징 하시오.
sns.countplot(data = chicago_df, y='Primary Type', order=primary_type)
plt.show()
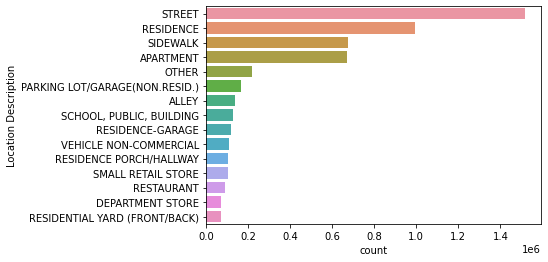
어디에서 가장 범죄가 많이 발생했는지, 범죄 장소(Location Descripton) 로 비주얼라이징 하시오.
location_oreder = chicago_df['Location Description'].value_counts().head(15).index
sns.countplot(data = chicago_df, y='Location Description', order=location_oreder)
plt.show()
데이터를 주기별로 분석해 보자

# 프로펫 라이브러리를 이용해서, 시카고 범죄 건수를 예측하려고 하는데
# 아래의 데이터 프레임에는 각 날짜별로 몇건의 범죄가 발생했는지의 데이터는 없음
# 따라서 각 날짜별로 몇건의 범죄가 발생했는지를 데이터 가공해서 가져와야 한다.
chicago_df.head(3)
| ID | Date | Block | Primary Type | Description | Location Description | Arrest | Domestic | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2006-04-02 13:00:00 | 4673626 | 2006-04-02 13:00:00 | 055XX N MANGO AVE | OTHER OFFENSE | HARASSMENT BY TELEPHONE | RESIDENCE | False | False |
| 2006-02-26 13:40:48 | 4673627 | 2006-02-26 13:40:48 | 065XX S RHODES AVE | NARCOTICS | MANU/DELIVER:CRACK | SIDEWALK | True | False |
| 2006-01-08 23:16:00 | 4673628 | 2006-01-08 23:16:00 | 013XX E 69TH ST | ASSAULT | AGGRAVATED: HANDGUN | OTHER | False | False |
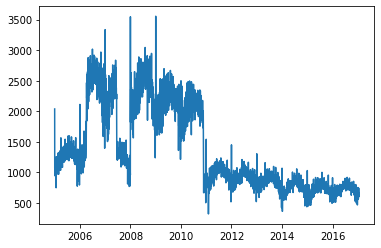
# resample 함수를 이용해서 날짜별로 범죄 건수를 세어보자!
# resample 함수를 사용하려면, 인덱스가 날짜 형식인, Datetimesindex 여야 한다.
df_day = chicago_df.resample('D').size()
plt.plot(df_day)
plt.show()
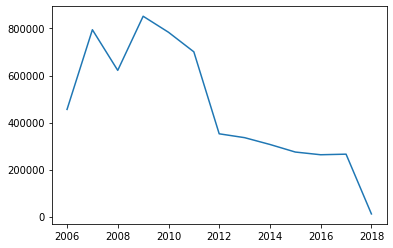
# resample 'Y' 는 년도다. 년도로 리샘플한 후, 각 년도별 몇개의 범죄 데이터를 가지고 있는지 확인한다.
df_year = chicago_df.resample('Y').size()
# 위의 데이터를 plot 으로 시각화 한다. 범죄횟수를 눈으로 확인하자.
plt.plot(df_year)
plt.show()
# 월별 범죄 발생 건수를 확인하자.
df_month = df_year = chicago_df.resample('M').size()
# 월별 범죄 발생 건수도 plot 으로 시각화 하자.
plt.plot(df_month)
plt.show()
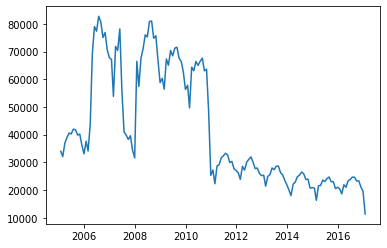
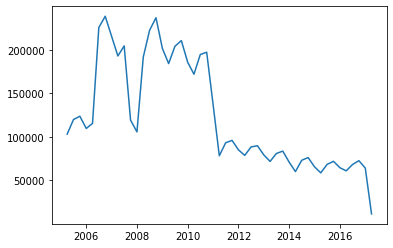
분기별 범죄 건수도 확인하자.
# 분기별 범죄 건수도 시각화 하자.
df_queter = chicago_df.resample('Q').size()
plt.plot(df_queter)
plt.show()
STEP #3: 데이터 준비
원별로(매달 말일) 주기로 하여 데이터프레임을 만들고, 인덱스를 리셋하시오.
chicago_prophet = chicago_df.resample('M').size()
chicago_prophet
Date
2005-01-31 33983
2005-02-28 32042
2005-03-31 36970
2005-04-30 38963
2005-05-31 40572
...
2016-09-30 23235
2016-10-31 23314
2016-11-30 21140
2016-12-31 19580
2017-01-31 11357
Freq: M, Length: 145, dtype: int64
프로펫 라이브러리를 사용하려면, 날짜 컬럼은 ‘ds’ 로, 에측하려는 수치는 ‘y’로 바꿔야 합니다(필수).
chicago_prophet = chicago_prophet.reset_index()
chicago_prophet.columns =['ds','y']
chicago_prophet
| ds | y | |
|---|---|---|
| 0 | 2005-01-31 | 33983 |
| 1 | 2005-02-28 | 32042 |
| 2 | 2005-03-31 | 36970 |
| 3 | 2005-04-30 | 38963 |
| 4 | 2005-05-31 | 40572 |
| ... | ... | ... |
| 140 | 2016-09-30 | 23235 |
| 141 | 2016-10-31 | 23314 |
| 142 | 2016-11-30 | 21140 |
| 143 | 2016-12-31 | 19580 |
| 144 | 2017-01-31 | 11357 |
145 rows × 2 columns
STEP #4: Prophet 으로 예측하기
prophet = Prophet()
# prophet으로 학습
prophet.fit(chicago_prophet)
INFO:numexpr.utils:NumExpr defaulting to 2 threads.
INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
<fbprophet.forecaster.Prophet at 0x7f1ca9a5de90>
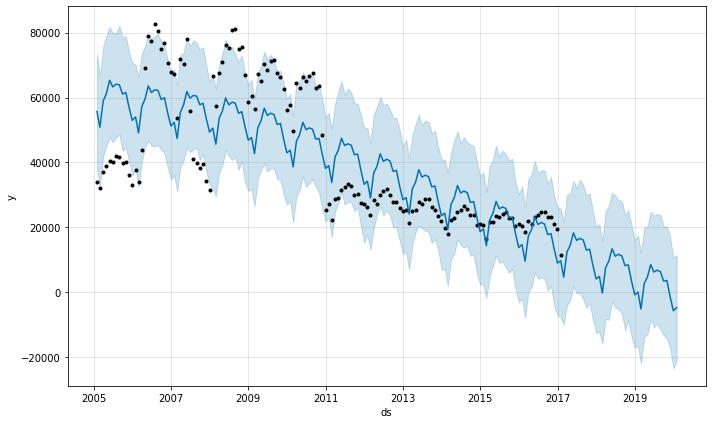
# 36개월로 해서 예측해보자.
future = prophet.make_future_dataframe(periods=36,freq='M')
forecast = prophet.predict(future)
prophet.plot(forecast)
plt.savefig('chart1.jpg') # 코랩과 버그가 있어 차트가 2개씩 뜨므로 하나는 저장하여 안보이게 할 수 있다.
댓글남기기