머신러닝 - K-Means
K-Means Clustering
Unsupervised Learning 이다.
k 개의 그룹을 만든다. 즉, 비슷한 특징을 갖는 것들끼리 묶는것
다음을 두개, 세개, 네개 그룹 등등 원하는 그룹으로 만들 수 있다.
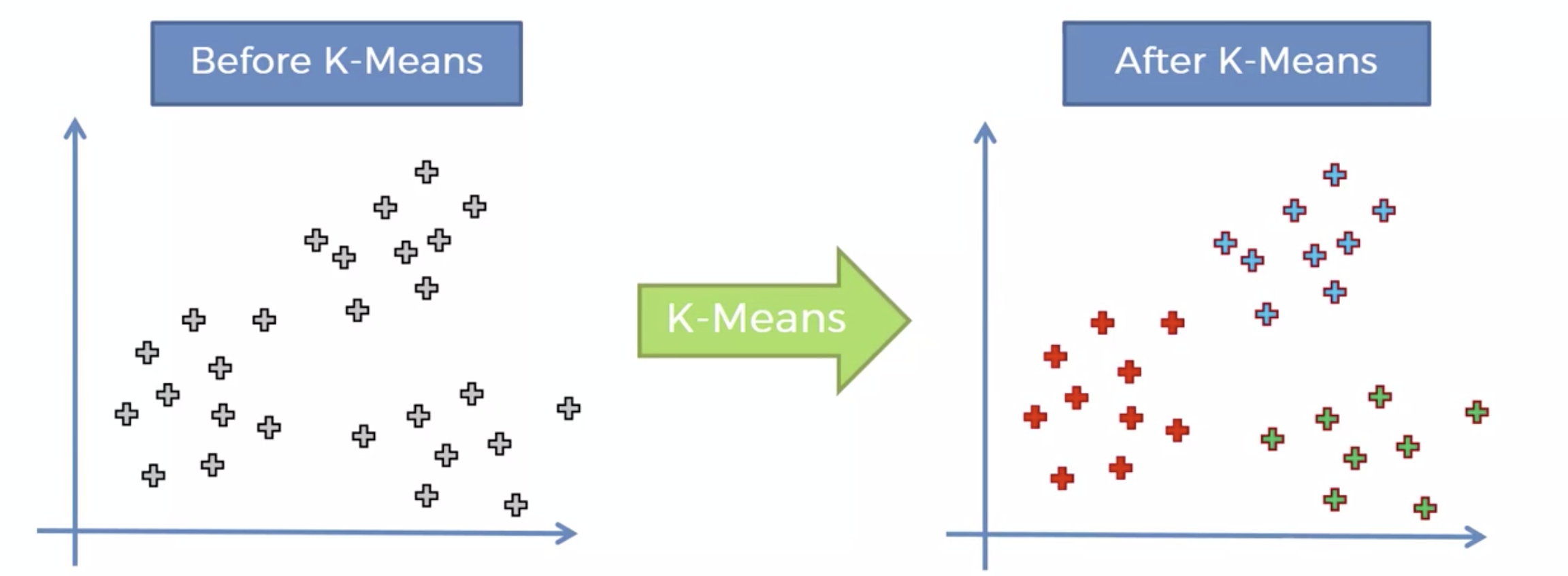
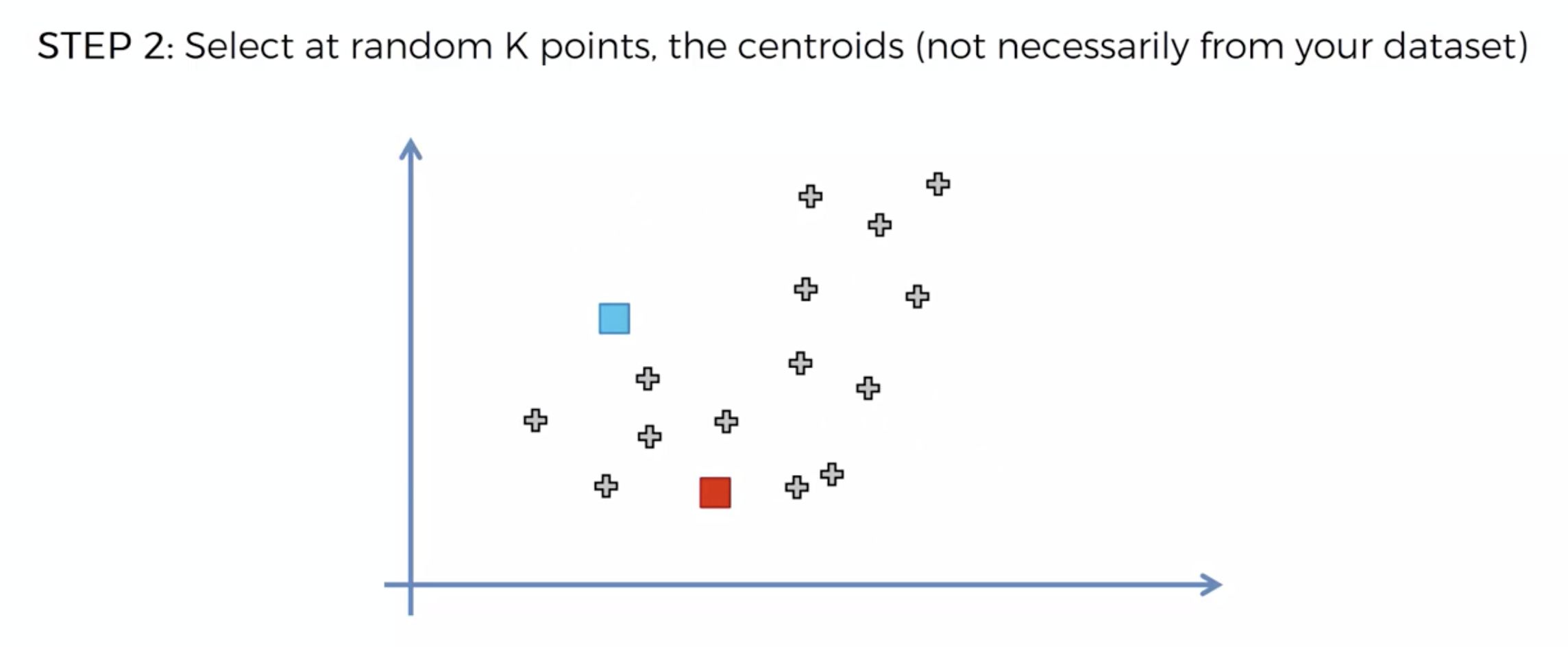
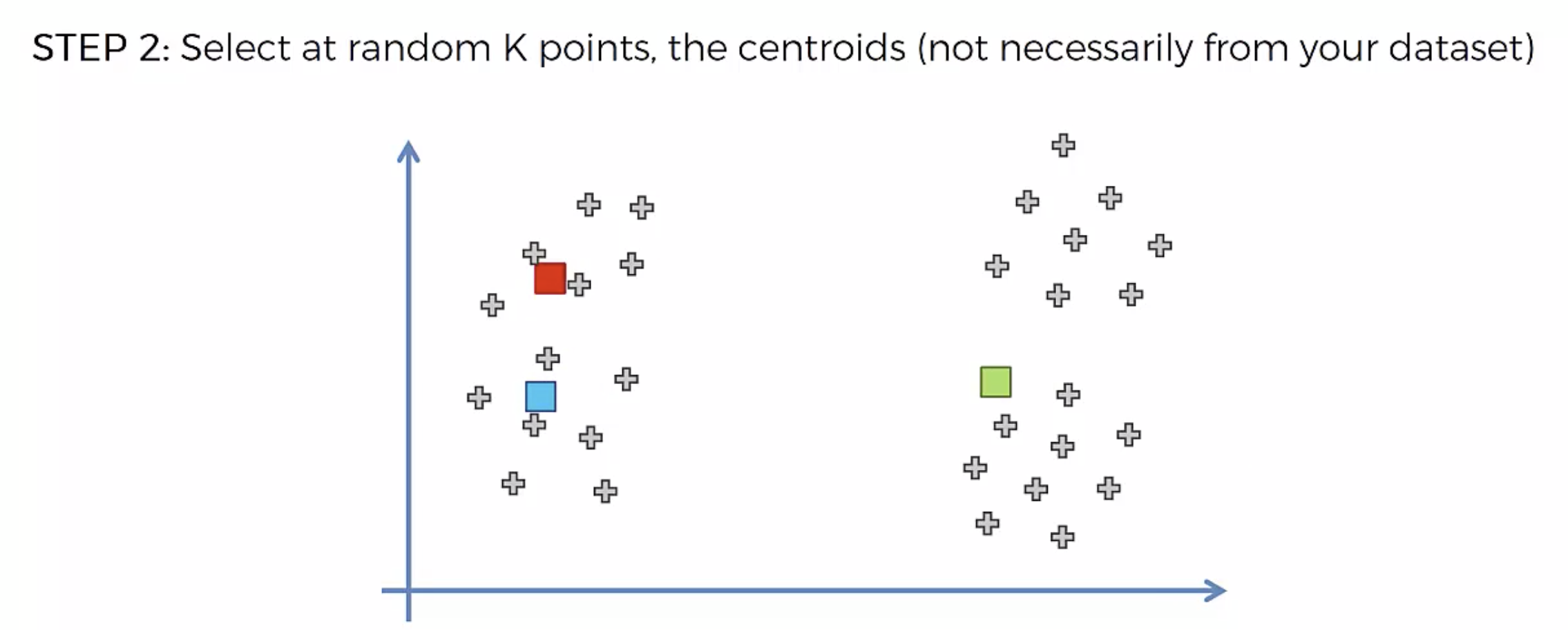
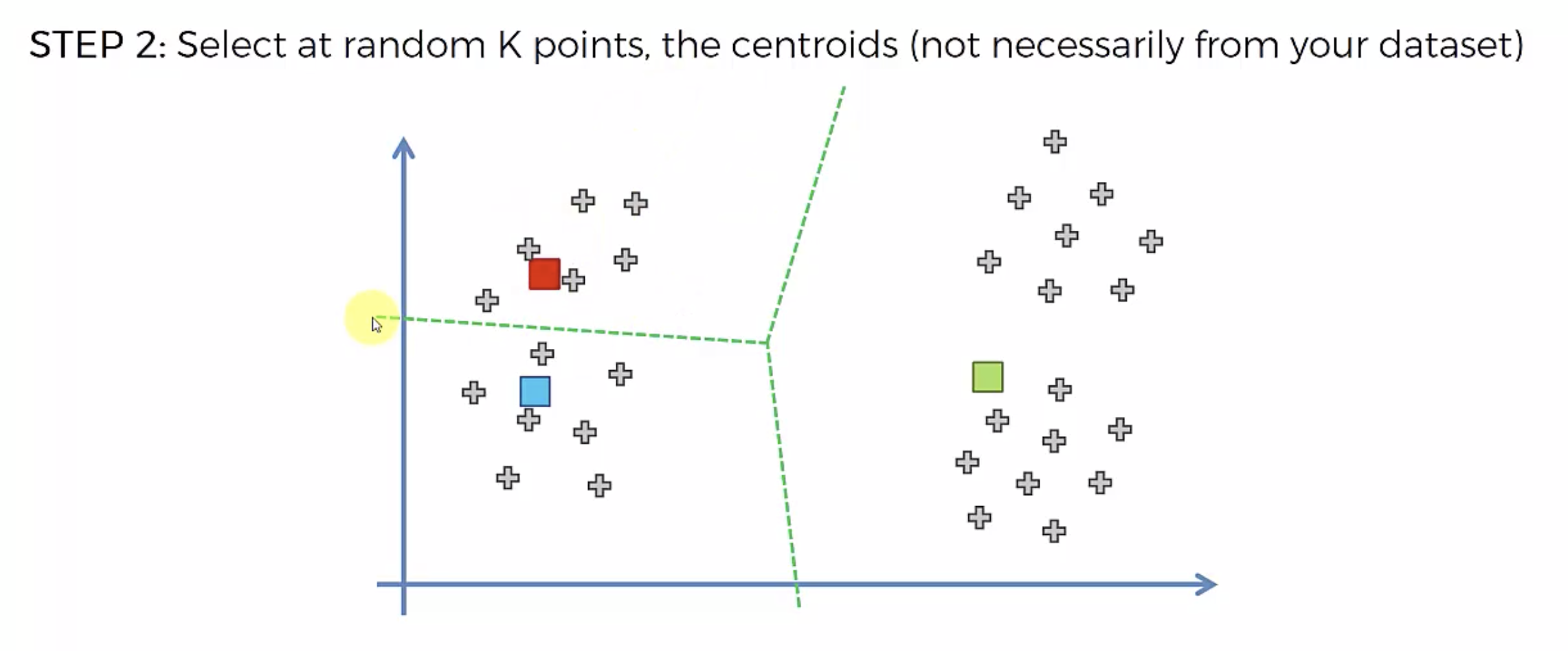
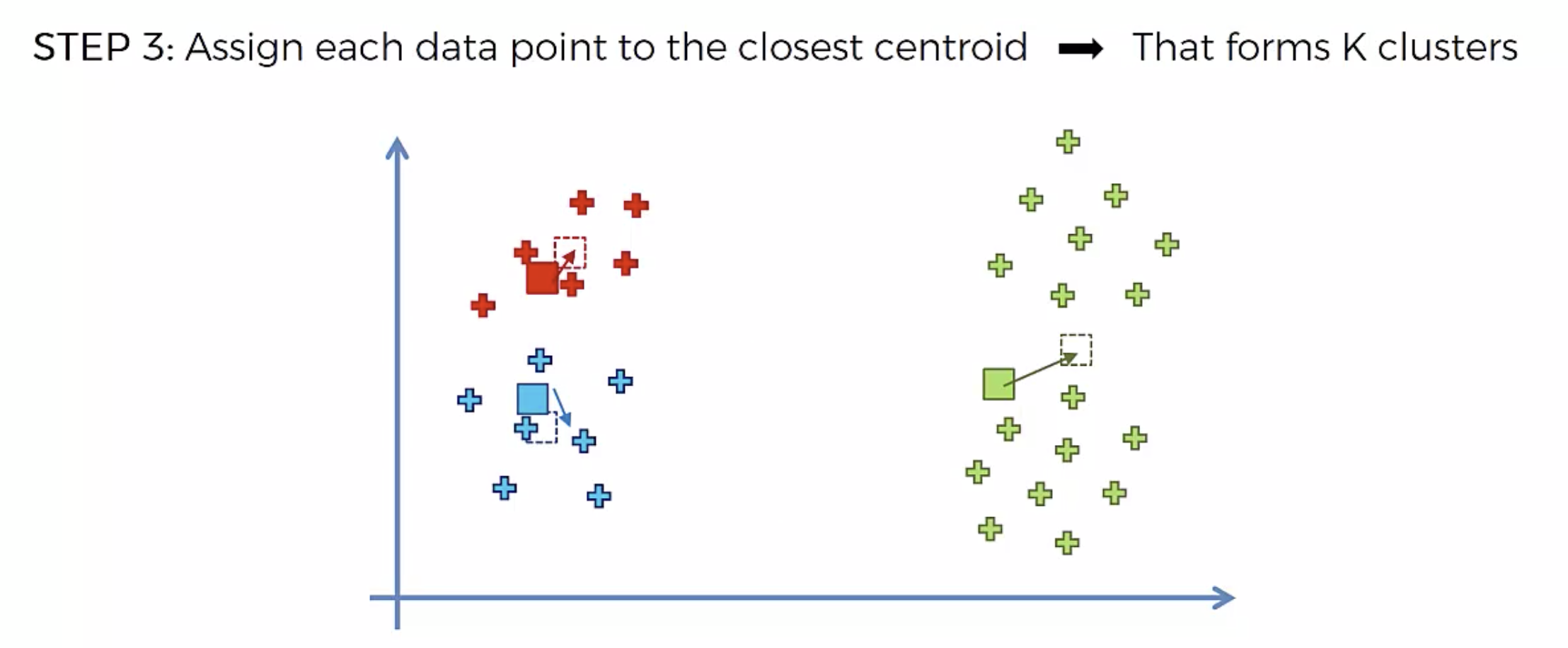
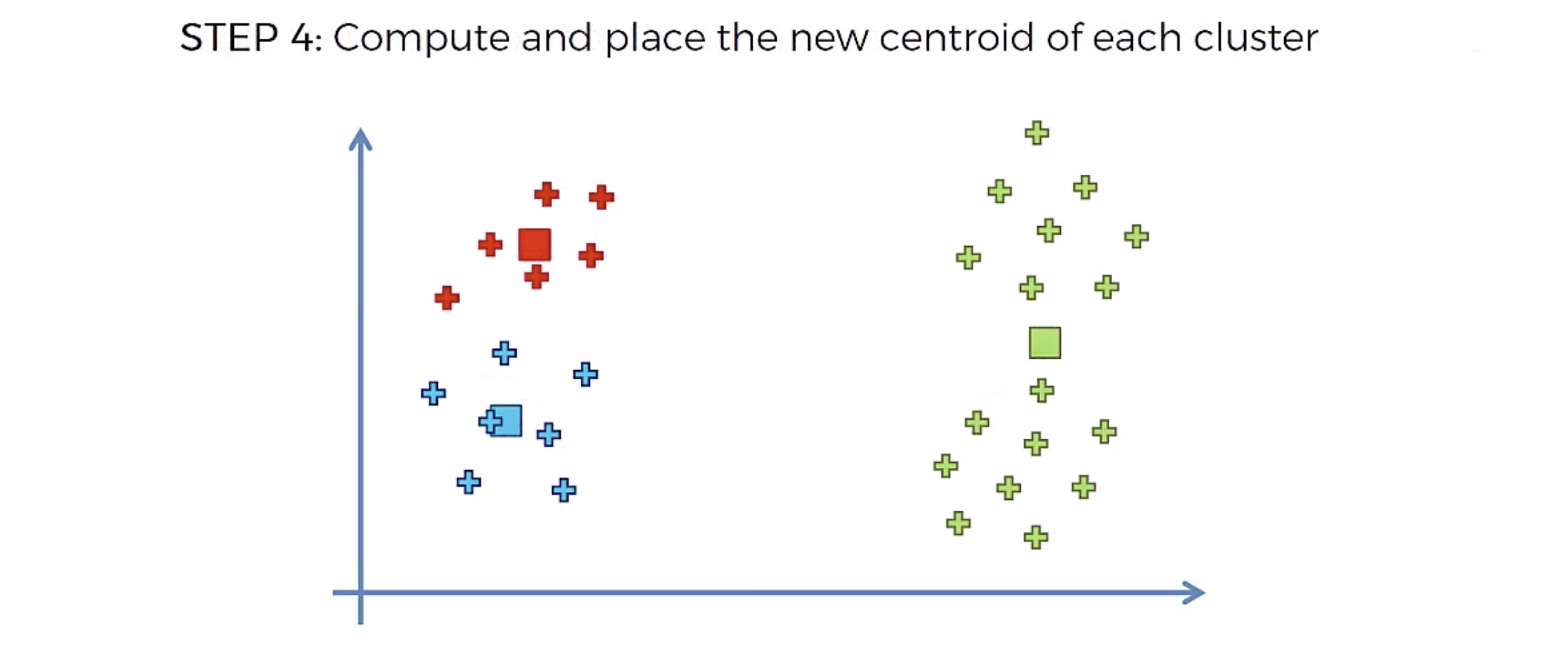
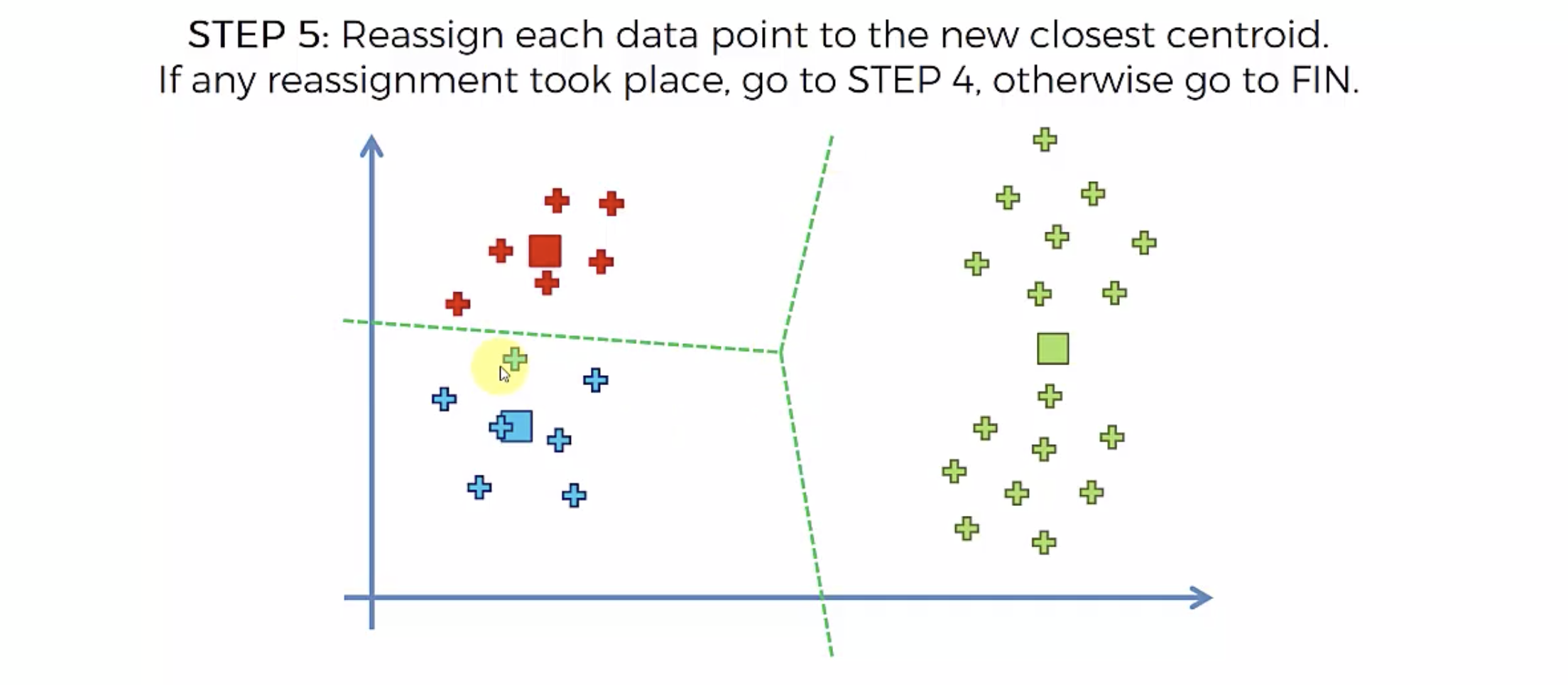
알고리즘


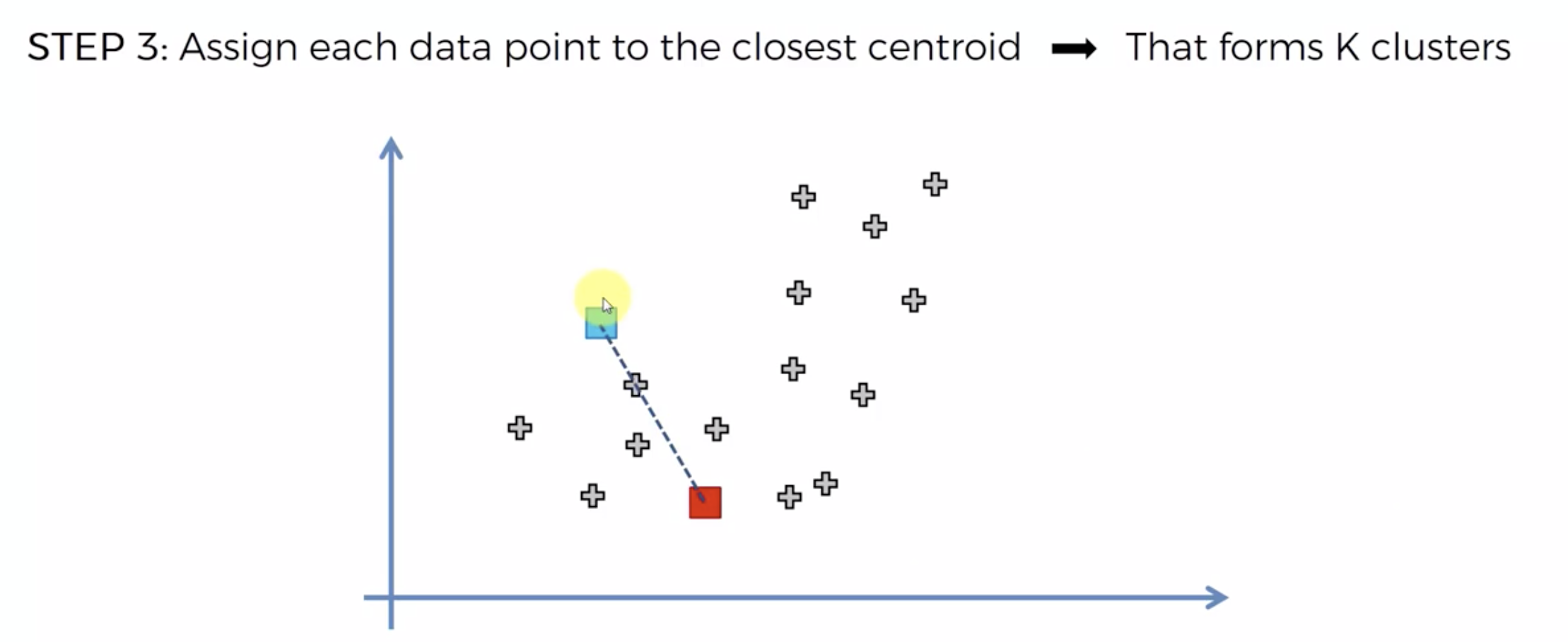
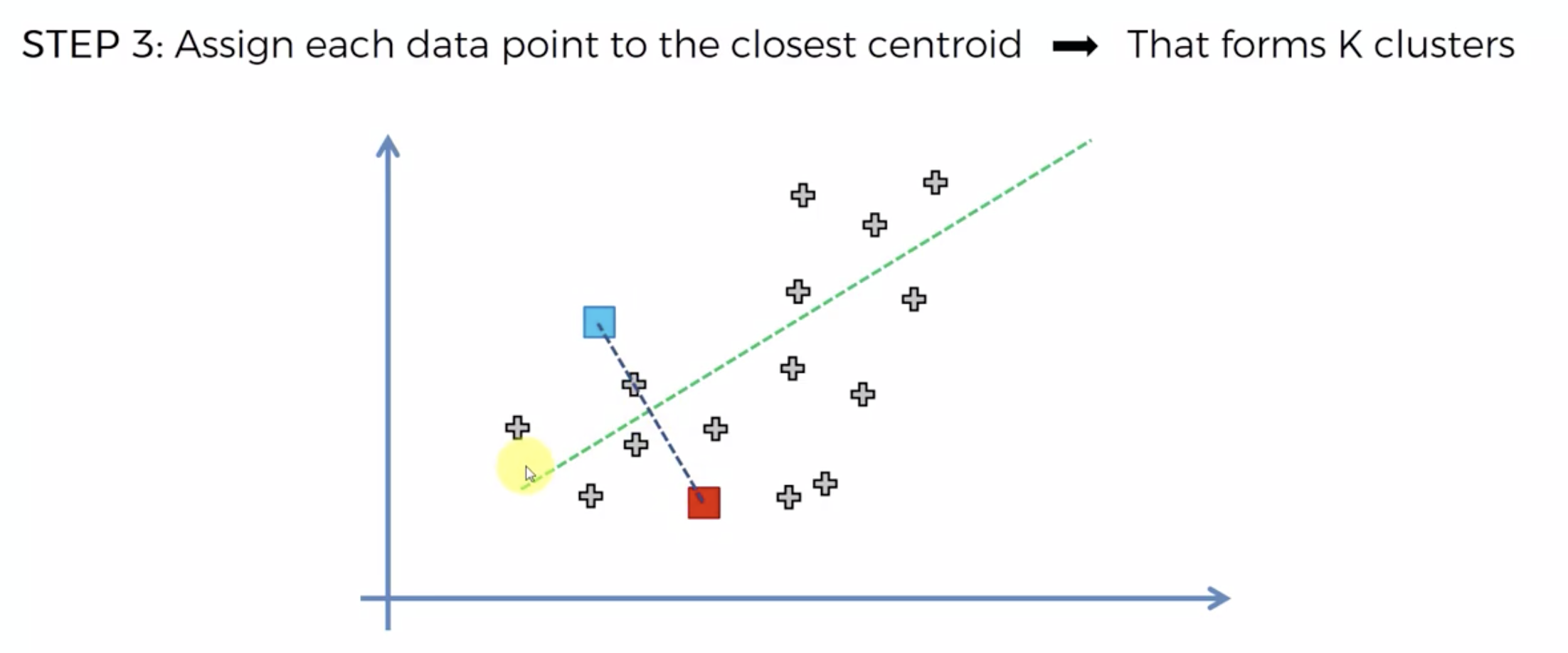
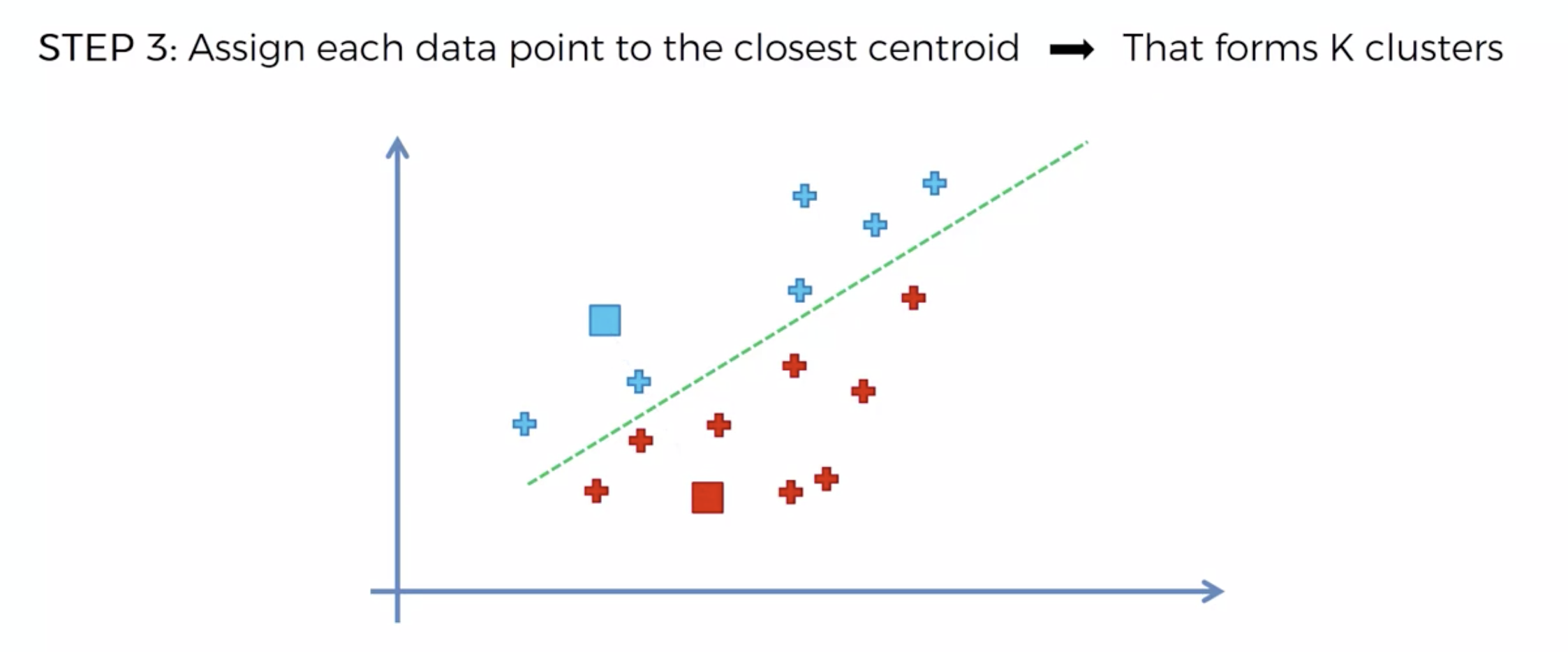
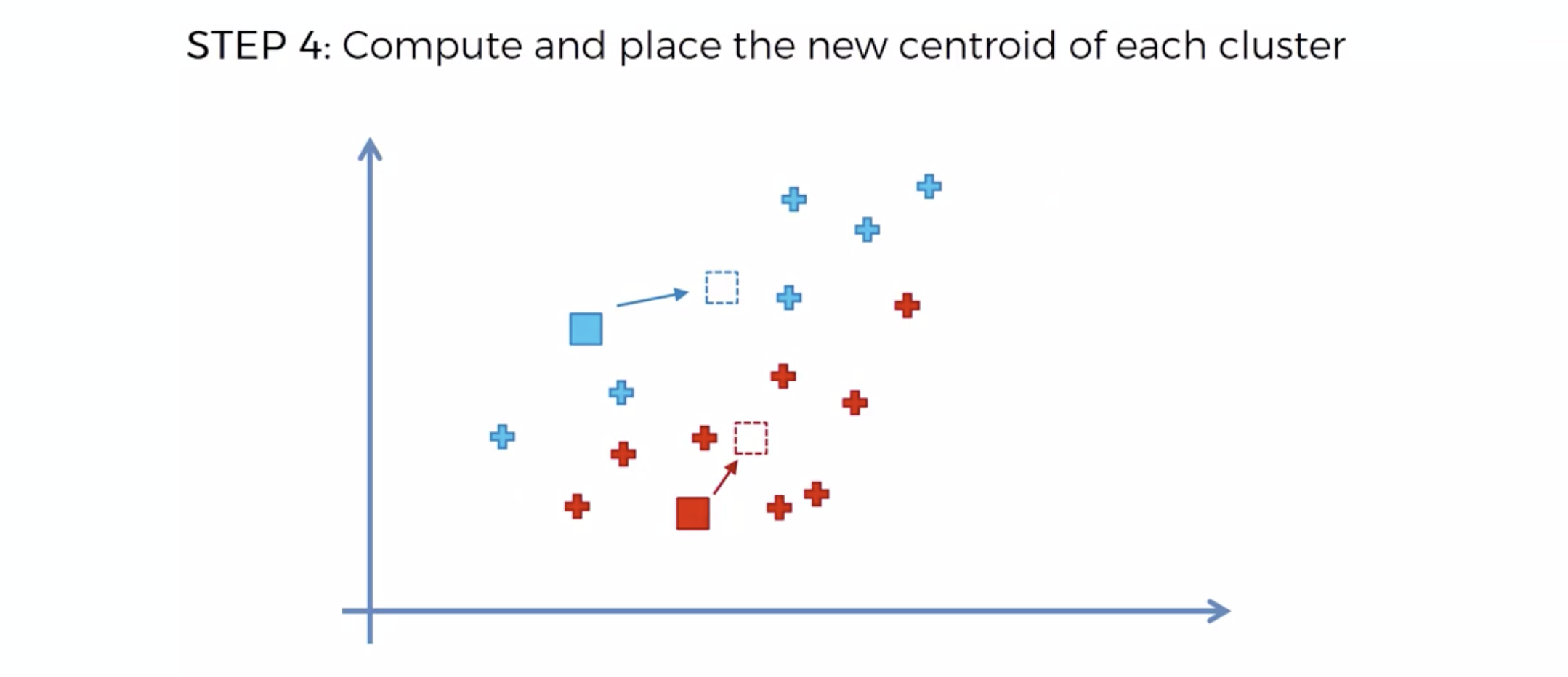
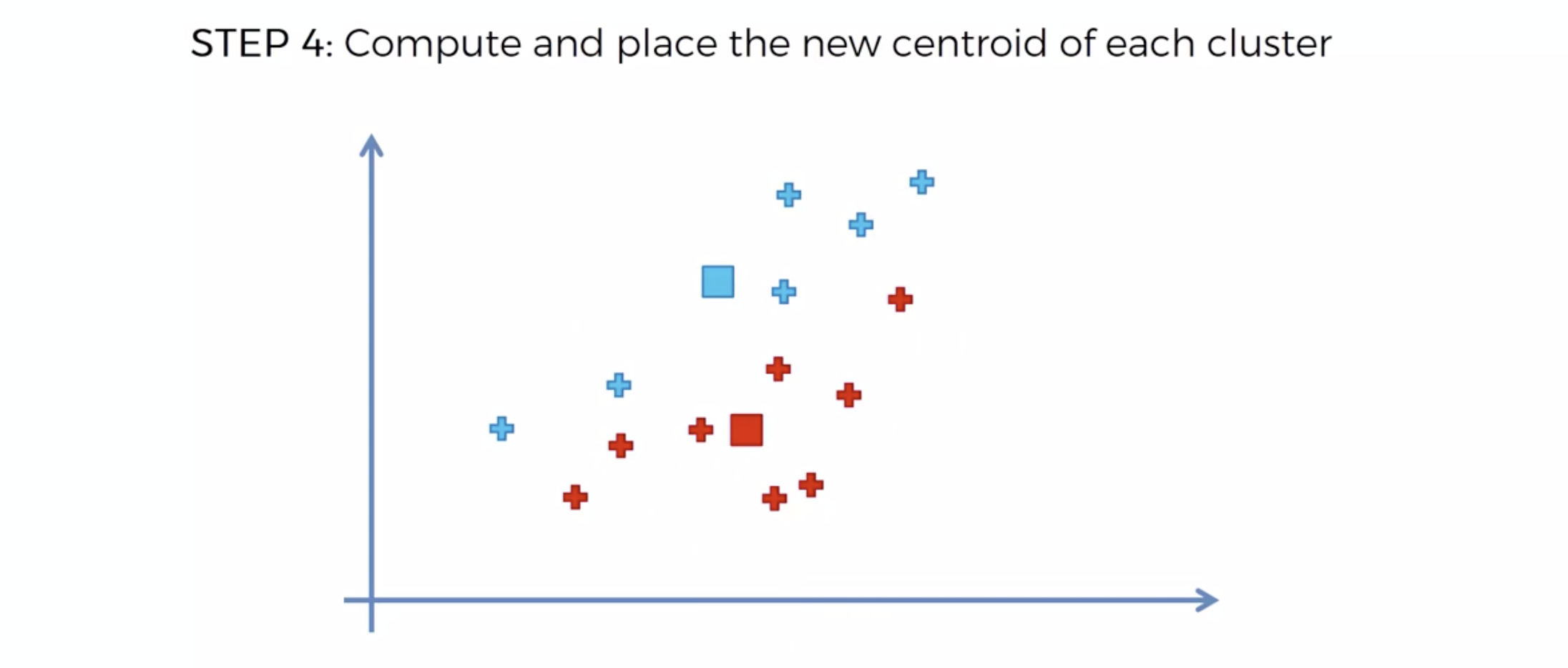
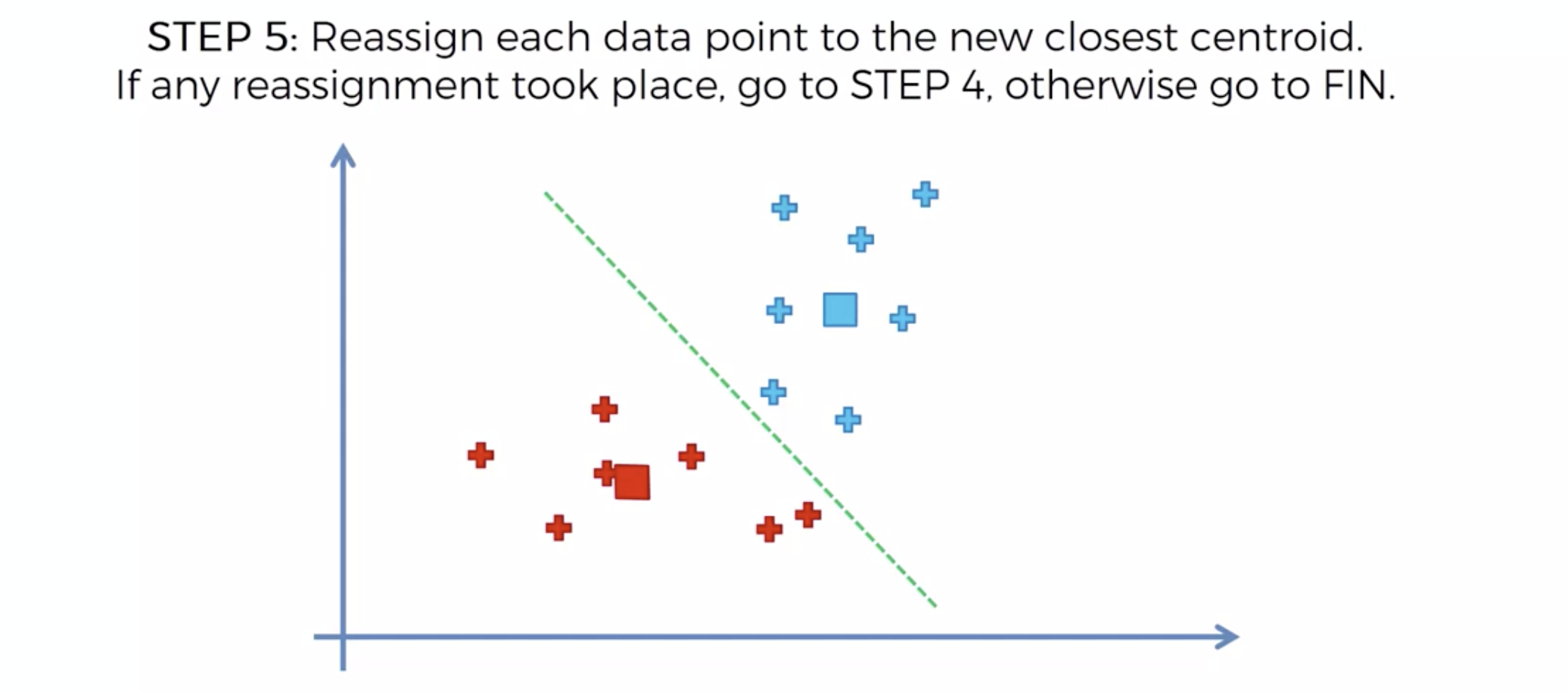
또다시 중심에 직교하는 선을 긋고, 자신의 영역안에 있는 것들을 자신의 색으로 바꾼다.
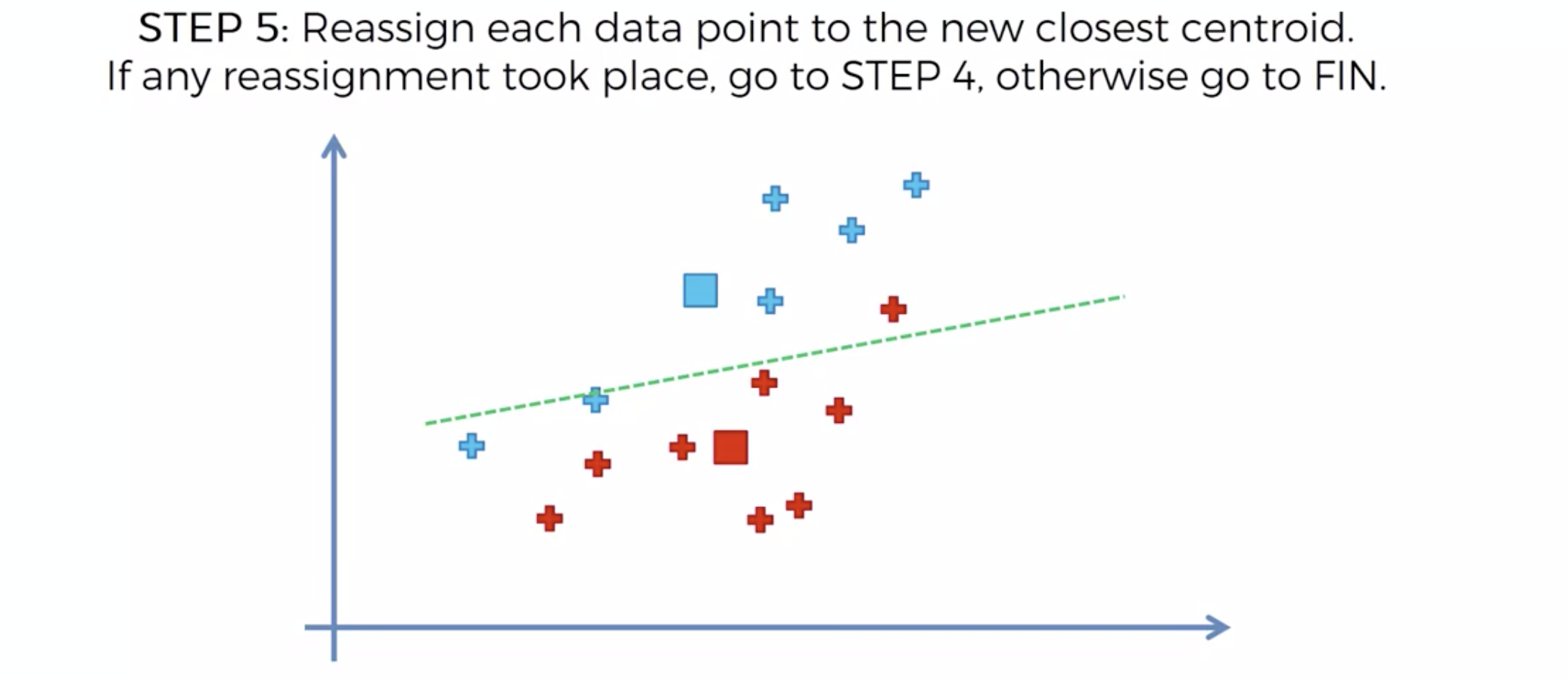
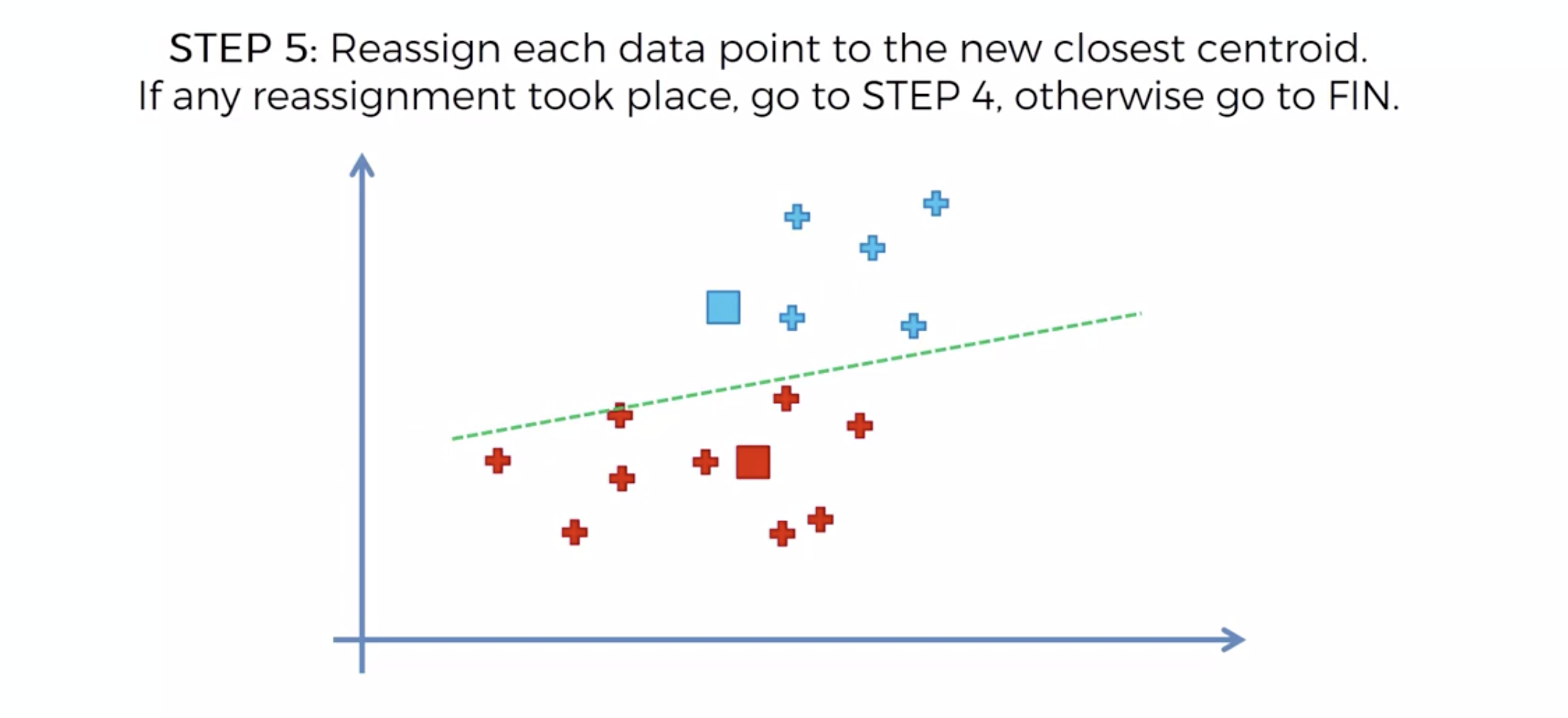
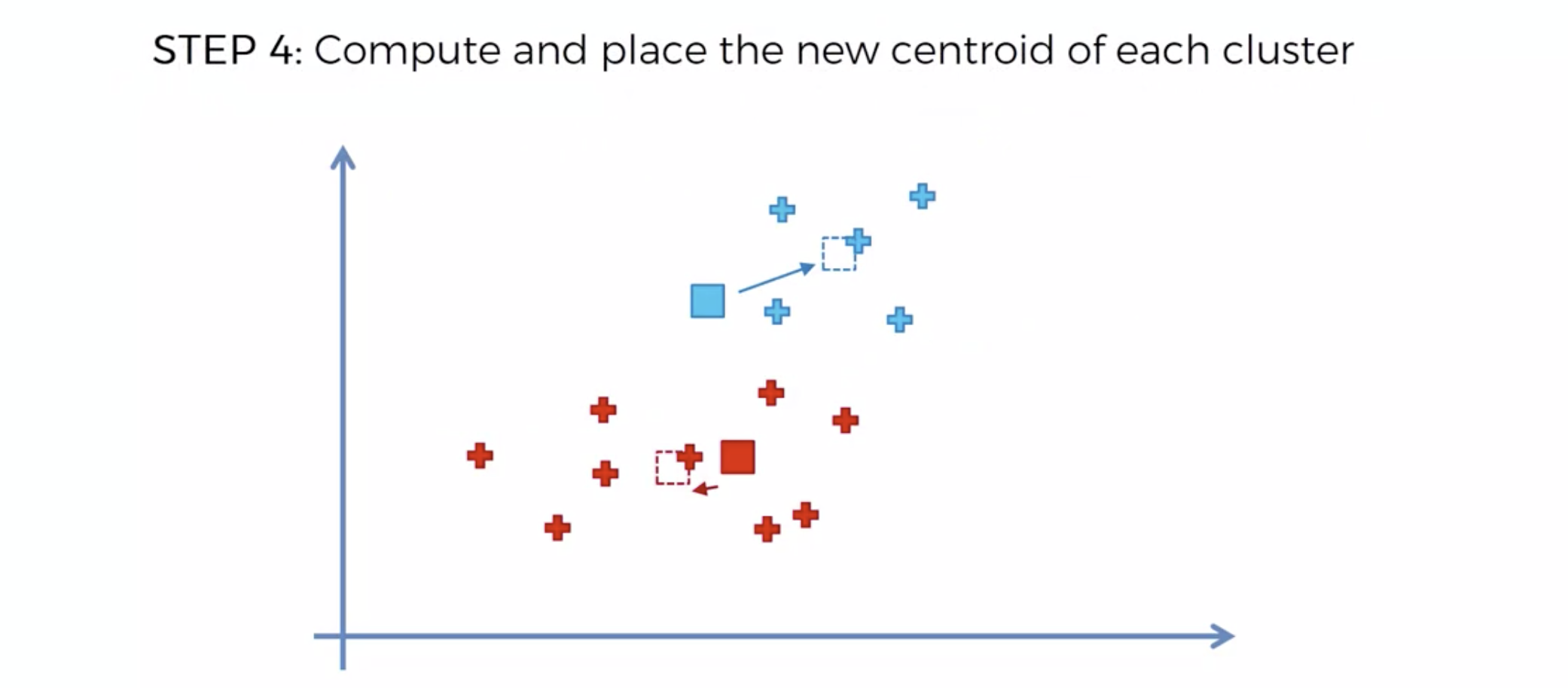
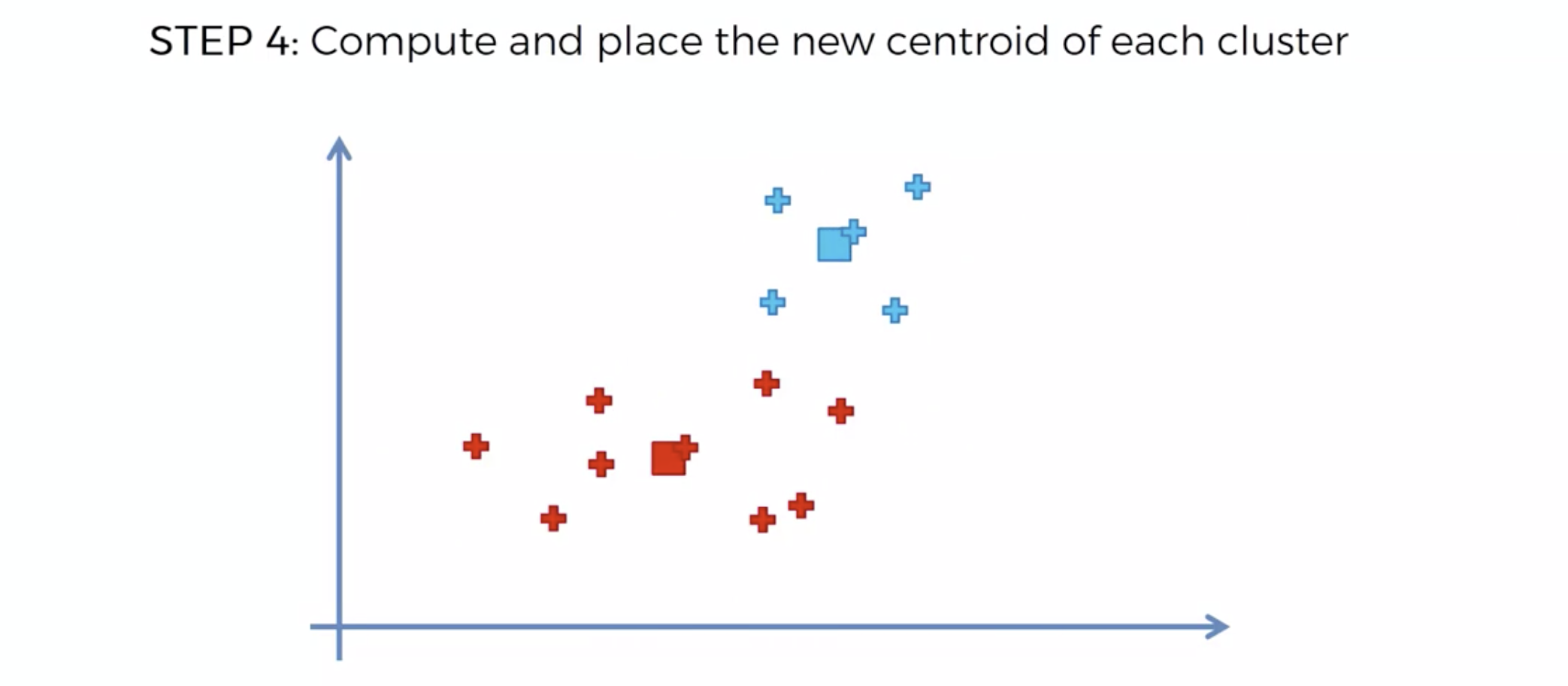
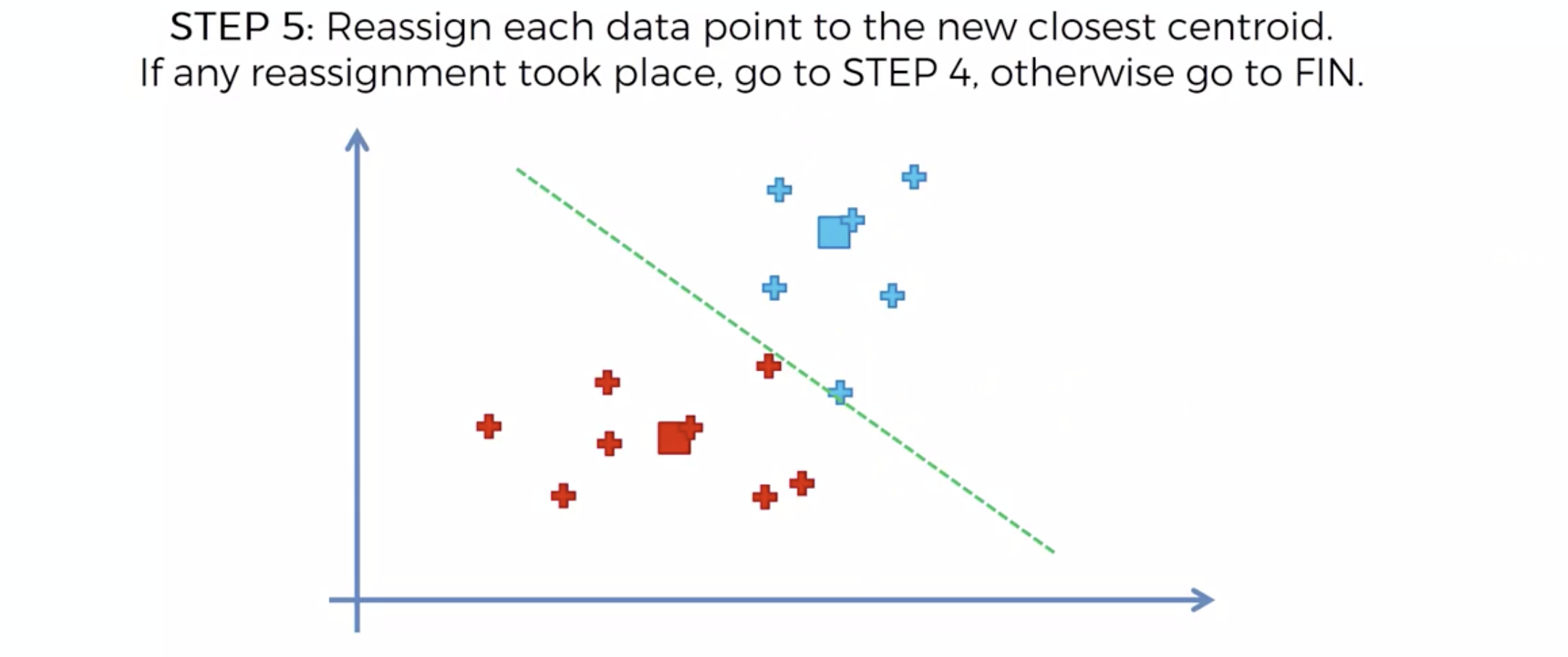
중심을 이동해서, 영역을 나눴는데, 나눈 영역안에 다른 카테고리가 더이상 나타나지 않으면, 끝낸다.
Random Initialization Trap
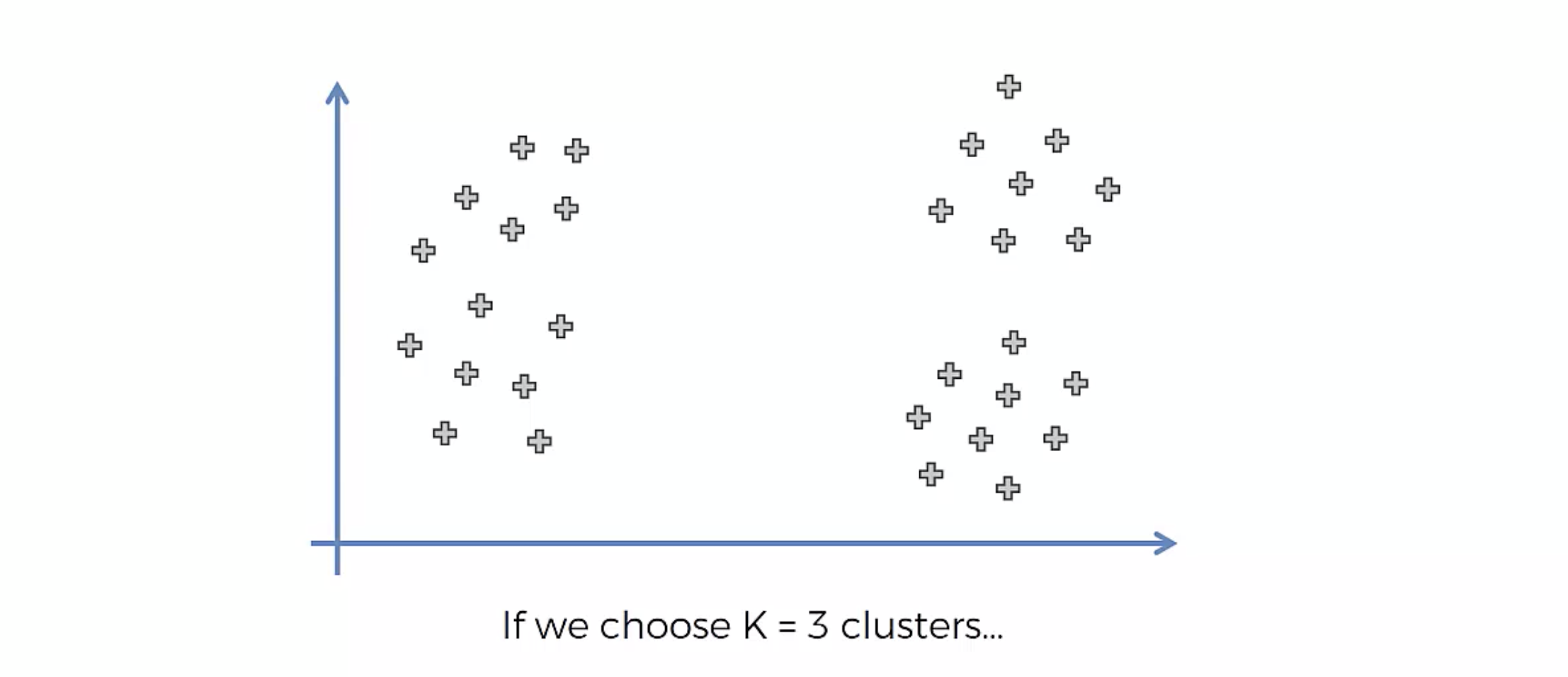
다음과 같은 데이터 분포가 있다고 치자.
우리가 원하는 클러스터링 그룹화는, 아래와 같은 것이다.
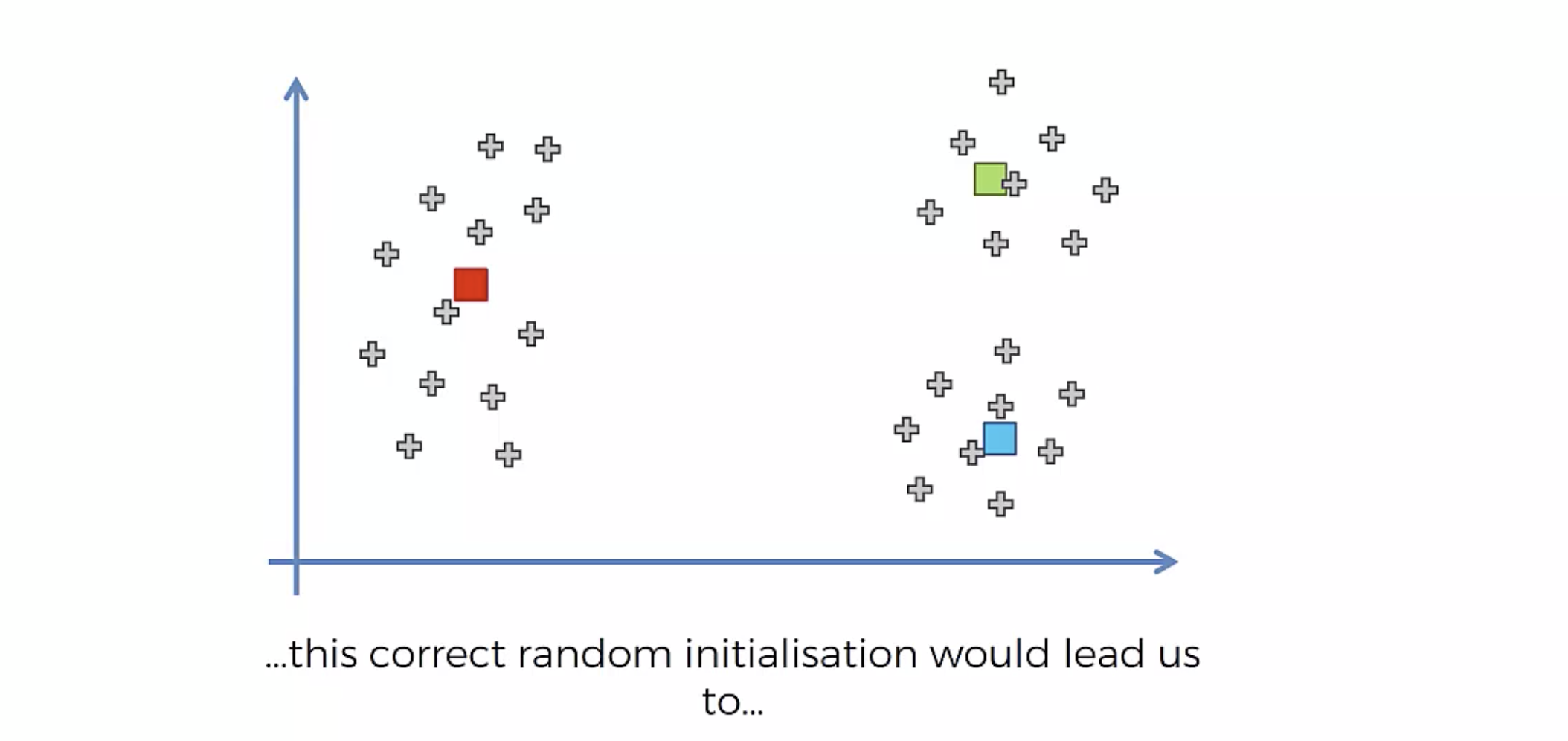
 원치 않는 그룹화가 되어버렸다.
원치 않는 그룹화가 되어버렸다.

위와 같은 문제는 해결한것이, K-Means++ 알고리즘이다.
Choosing the right number of clusters
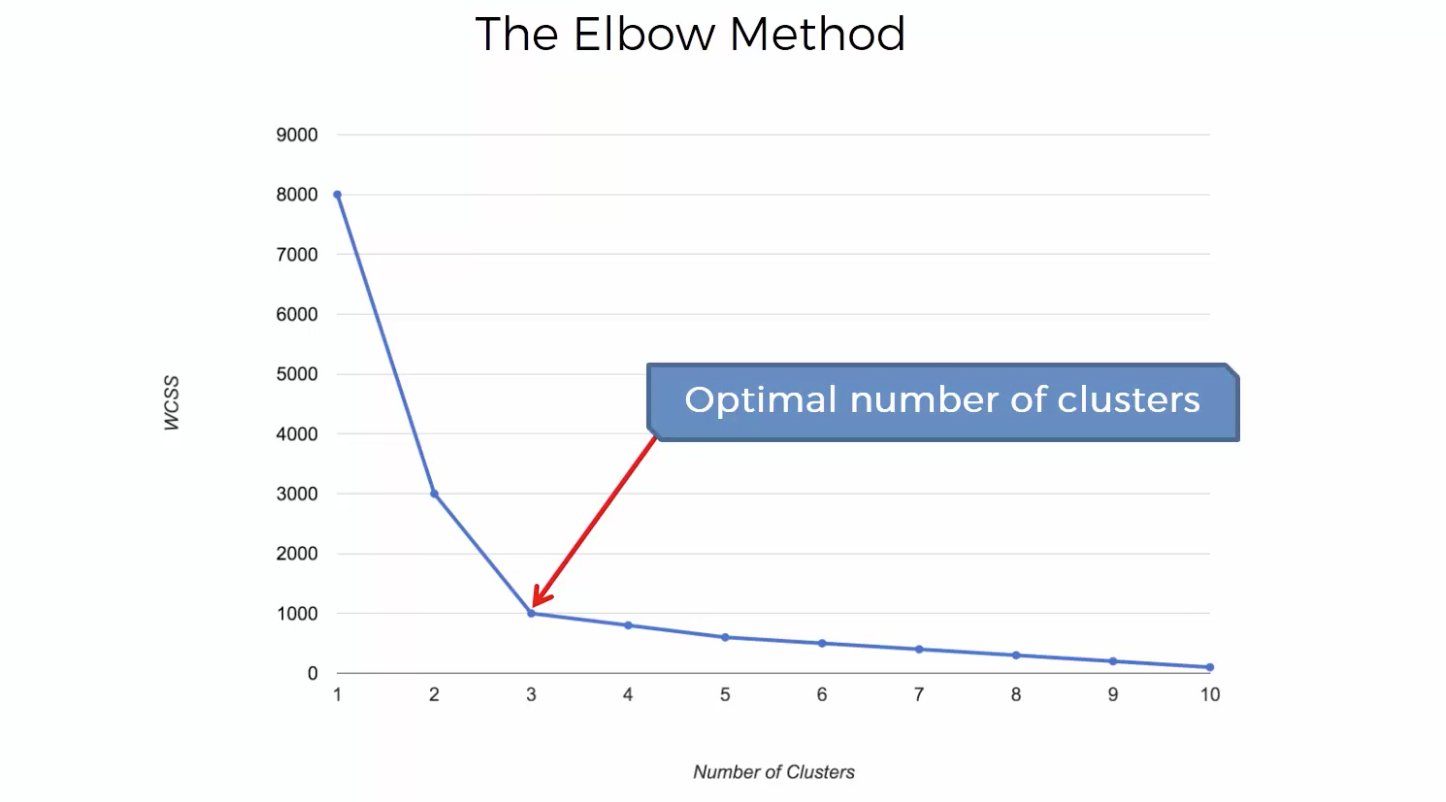
몇개로 분류할지는 어떻게 결정하는가? K의 갯수를 정하는 방법
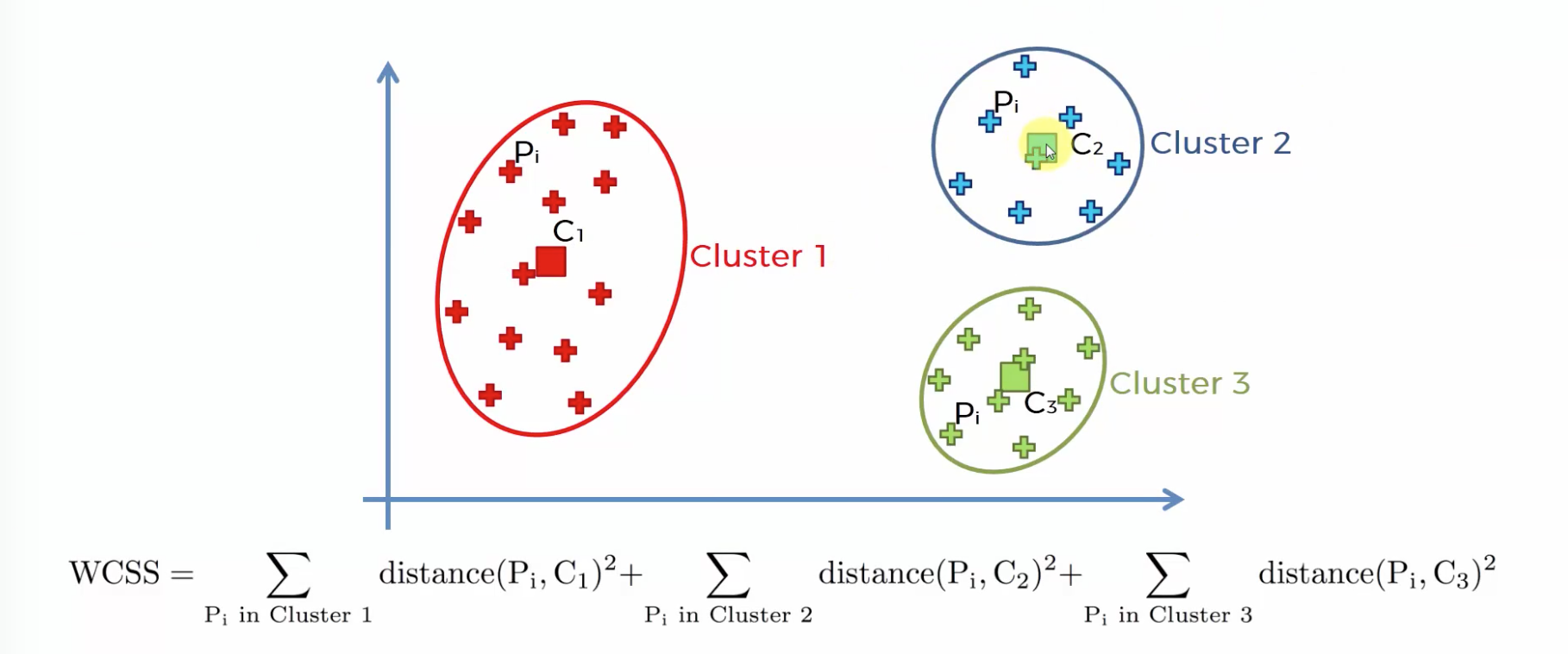
within-cluster sums of squares
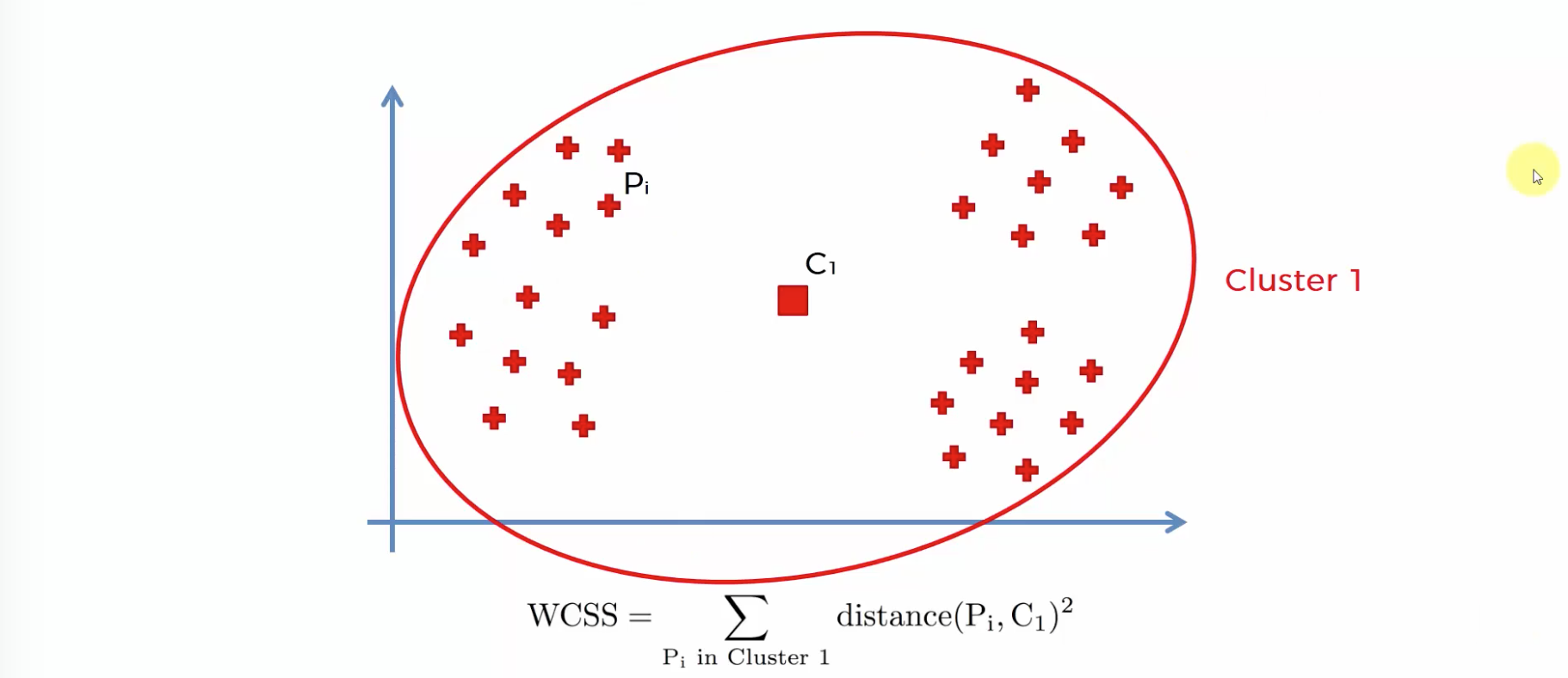
센터가 원소들과의 거리가 멀수록 값이 커진다. 따라서 최소값에 가까워지는 갯수를 뽑되, 갯수가 너무 많아지면 차별성이 없어진다.
K-Means 모델링
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
df = pd.read_csv('Mall_Customers.csv')
df.head()
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | |
|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 |
| 1 | 2 | Male | 21 | 15 | 81 |
| 2 | 3 | Female | 20 | 16 | 6 |
| 3 | 4 | Female | 23 | 16 | 77 |
| 4 | 5 | Female | 31 | 17 | 40 |
# Nan 있는지 확인
df.isna().sum()
CustomerID 0
Genre 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64
1. 데이터 가공
# Unsupervised learnig 이므로 , y값은 존재하지 않는다.
# X 값 셋팅
X = df.iloc[:,3:]
2. 모델링
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3, random_state=42)
y_pred = kmeans.fit_predict(X)
df['group'] = y_pred
# y_pred 의 값은, 각 행(사람)의 그룹 정보를 가지고 있다.
# 따라서 이 그룹정보는 원래의 데이터 프레임에 추가를 해줘야 이용할 수 있다.
df
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | group | |
|---|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 | 0 |
| 1 | 2 | Male | 21 | 15 | 81 | 0 |
| 2 | 3 | Female | 20 | 16 | 6 | 0 |
| 3 | 4 | Female | 23 | 16 | 77 | 0 |
| 4 | 5 | Female | 31 | 17 | 40 | 0 |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 | 2 |
| 196 | 197 | Female | 45 | 126 | 28 | 1 |
| 197 | 198 | Male | 32 | 126 | 74 | 2 |
| 198 | 199 | Male | 32 | 137 | 18 | 1 |
| 199 | 200 | Male | 30 | 137 | 83 | 2 |
200 rows × 6 columns
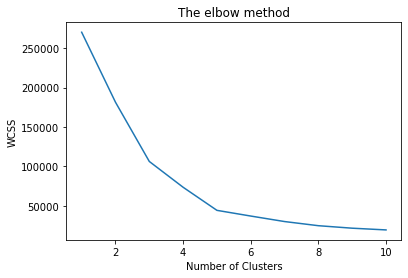
# 적절한 k 값을 찾기위해서는, WCSS 값을 확인해야 한다.
# 따라서 K를 1부터 10까지 다 수행해서, WCSS값은 리스트에 저장한다.
wcss = []
for k in range(1,11):
kmeans = KMeans(n_clusters =k, random_state=42)
# Wcss 값만 확인 할거니까, fit 함수만 이용하면 된다.
kmeans.fit(X)
wcss.append(kmeans.inertia_)
C:\Users\5-15\Anaconda3\lib\site-packages\sklearn\cluster\_kmeans.py:881: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=1.
warnings.warn(
# 엘보우 메소드를 이용하기 위해서, 차트로 표시한다.
plt.plot(range(1,11),wcss)
plt.title('The elbow method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()
kmeans = KMeans(n_clusters=5, random_state=42)
y_pred = kmeans.fit_predict(X)
df['Group'] = y_pred
df
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | group | Group | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 | 0 | 2 |
| 1 | 2 | Male | 21 | 15 | 81 | 0 | 3 |
| 2 | 3 | Female | 20 | 16 | 6 | 0 | 2 |
| 3 | 4 | Female | 23 | 16 | 77 | 0 | 3 |
| 4 | 5 | Female | 31 | 17 | 40 | 0 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 | 2 | 4 |
| 196 | 197 | Female | 45 | 126 | 28 | 1 | 1 |
| 197 | 198 | Male | 32 | 126 | 74 | 2 | 4 |
| 198 | 199 | Male | 32 | 137 | 18 | 1 | 1 |
| 199 | 200 | Male | 30 | 137 | 83 | 2 | 4 |
200 rows × 7 columns
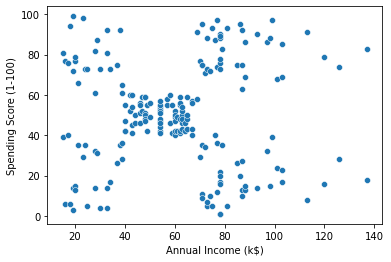
3. 데이터 시각화 및 실습
sb.scatterplot(data= df,x='Annual Income (k$)',y='Spending Score (1-100)')
plt.show()
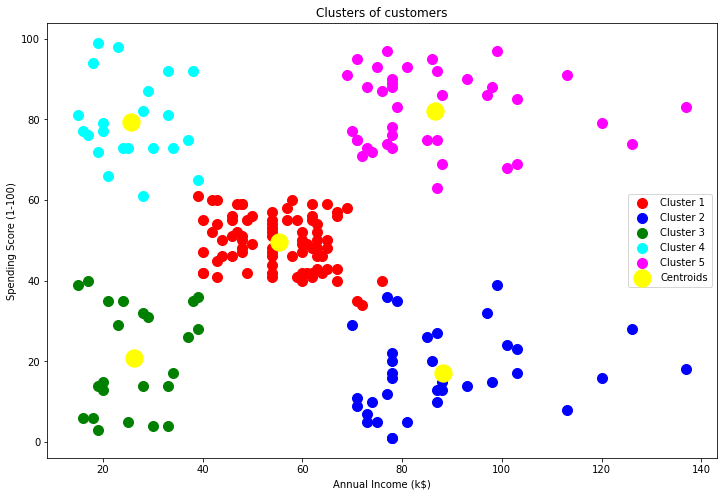
plt.figure(figsize=[12,8])
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()

# 1. 그룹이 3인 사람들의 데이터를 가져오세요
df_3 = df[df['Group'] == 3]
# 2. 그룹이 3인 사람들의 수입 평균은 얼마입니까?
df_3['Annual Income (k$)'].mean()
25.727272727272727
# 3. 그룹별 소비지표를 나타내되, 평균값과 최대값 두개를 보여주세요.
pd.pivot_table(df,index=['Group'],aggfunc=[np.mean,np.max],values='Spending Score (1-100)')
| mean | amax | |
|---|---|---|
| Spending Score (1-100) | Spending Score (1-100) | |
| Group | ||
| 0 | 49.518519 | 61 |
| 1 | 17.114286 | 39 |
| 2 | 20.913043 | 40 |
| 3 | 79.363636 | 99 |
| 4 | 82.128205 | 97 |
# 4. 각 그룹별 수입과 소비지표의 평균을 구하세요
pd.pivot_table(df,index=['Group'],aggfunc=[np.mean],values=['Annual Income (k$)','Spending Score (1-100)'])
| mean | ||
|---|---|---|
| Annual Income (k$) | Spending Score (1-100) | |
| Group | ||
| 0 | 55.296296 | 49.518519 |
| 1 | 88.200000 | 17.114286 |
| 2 | 26.304348 | 20.913043 |
| 3 | 25.727273 | 79.363636 |
| 4 | 86.538462 | 82.128205 |
댓글남기기