머신러닝 - Hierarchical Clustering
Hierarchical Clustering
Library 임포트
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset 읽어오기
df = pd.read_csv('Mall_Customers.csv')
X = df.iloc[:,3:]
X.head(3)
| Annual Income (k$) | Spending Score (1-100) | |
|---|---|---|
| 0 | 15 | 39 |
| 1 | 15 | 81 |
| 2 | 16 | 6 |
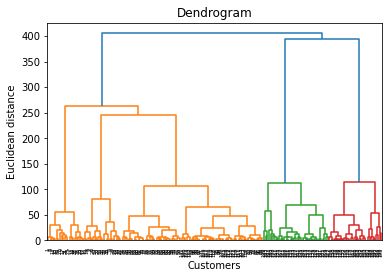
Dendrogram 을 그리고, 최적의 클러스터 갯수를 찾아보자.
import scipy.cluster.hierarchy as sch
sch.dendrogram(sch.linkage(X,method='ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Euclidean distance')
plt.show()
Training the Hierarchical Clustering model
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters=5)
y_pred = hc.fit_predict(X)
df['Group'] = y_pred
df
| CustomerID | Genre | Age | Annual Income (k$) | Spending Score (1-100) | Group | |
|---|---|---|---|---|---|---|
| 0 | 1 | Male | 19 | 15 | 39 | 4 |
| 1 | 2 | Male | 21 | 15 | 81 | 3 |
| 2 | 3 | Female | 20 | 16 | 6 | 4 |
| 3 | 4 | Female | 23 | 16 | 77 | 3 |
| 4 | 5 | Female | 31 | 17 | 40 | 4 |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | 196 | Female | 35 | 120 | 79 | 2 |
| 196 | 197 | Female | 45 | 126 | 28 | 0 |
| 197 | 198 | Male | 32 | 126 | 74 | 2 |
| 198 | 199 | Male | 32 | 137 | 18 | 0 |
| 199 | 200 | Male | 30 | 137 | 83 | 2 |
200 rows × 6 columns
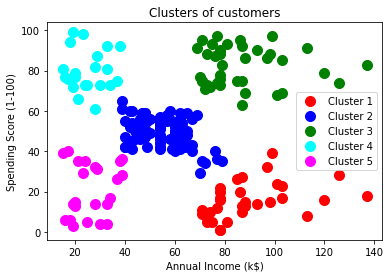
그루핑 정보를 확인
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
댓글남기기