파이썬 - 넘파이
PYTHON PROGRAMMING FUNDAMENTALS
다음 토픽을 다룹니다.:
- Numpy 기초
- Built-in methods and functions
- shape, length and type of Numpy arrays
- Reshape
- Minimum and maximum
- Mathematical Operations
- Indexing and slicing
- Selection
NUMPY BASICS
- NumPy는 다차원 배열을 처리할 수 있는 선형대수학(Linear Algebra) 라이브러리입니다.
- 다음이 실행이 안되면 아나콘다프롬프트에서 conda install numpy 를 실행하여 설치합니다.
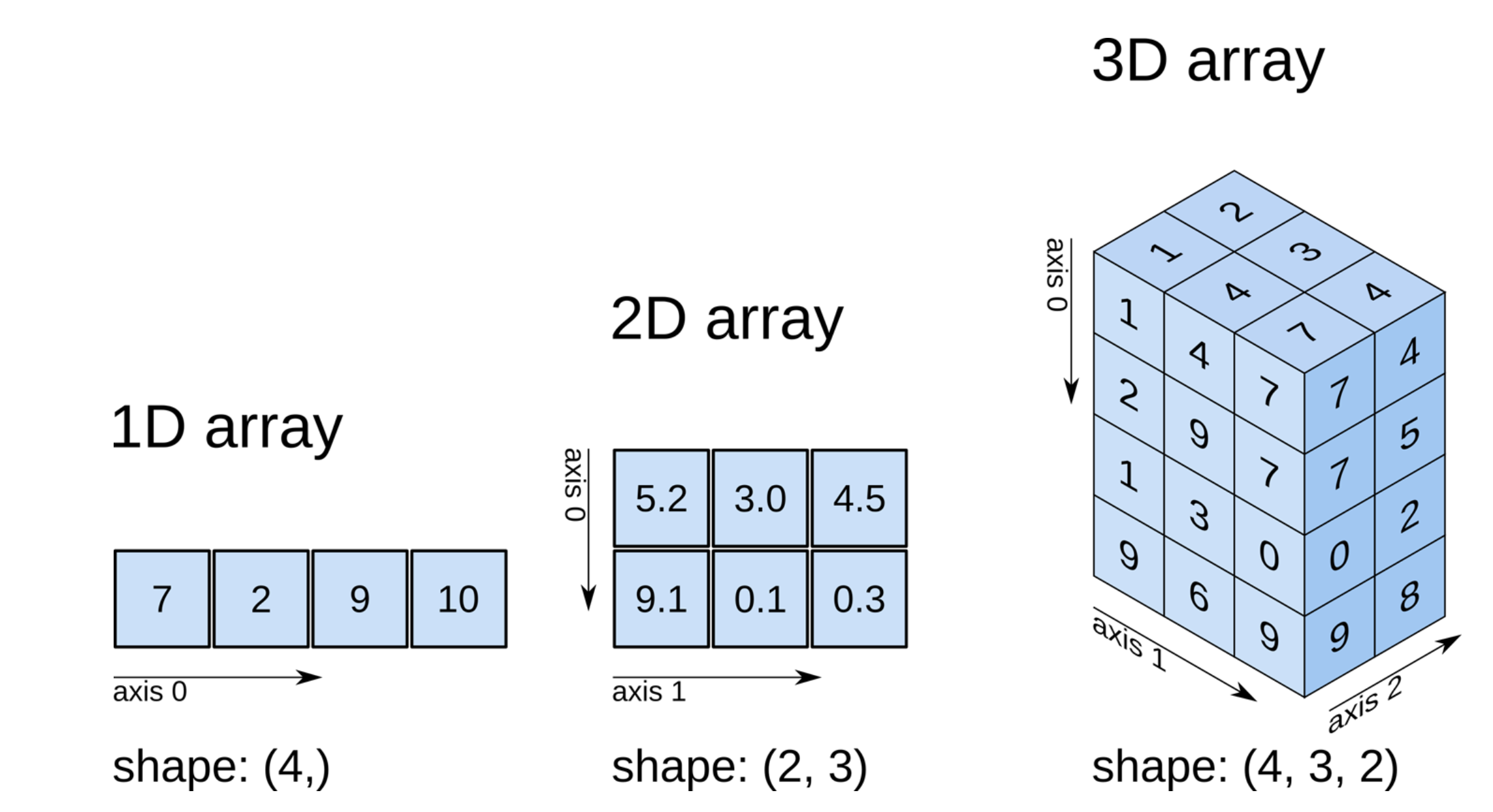
#1D array 표현법
#1D array => 벡터.
#2D array => 메트릭스
#(4) = x => 숫자로 표현됨 (4,) 로 표현.
(4, )
(4,)
import numpy as np
a = [1,2,3,4,5]
# 넘파이의 1차원 배열로 만드는 방법 : 리스트를 넣어준다.
# 1차원 어레이의 경우 변수명은 소문자로 대부분 지정.
x = np.array([1,2,3,4,5])
# array( 는, 넘파이 어레이.
# numpy 어레이와 리스트의 차이.
len(a)
5
len(x)
5
#속성값 정의 가능
x.size
5
#shape를 통하여 몇 차원 배열인지 확인가능.
x.shape
(5,)
# dtype을 통하여 몇 비트로 저장하는지 확인가능, 원소의 속성 확인 가능.
x.dtype
dtype('int32')
#넘파이의 어레이를 만드는 방법 : 2차원 행렬 => 2차원 리스트를 넣어준다.
b= [[1,2],[3,4]]
#2차원 어레이의 변수 저장은 대문자로 한다.
X = np.array(b)
X
array([[1, 2],
[3, 4]])
# 넘파이 어레이 차이점
X.size
4
len(b)
2
X.shape
(2, 2)
X.dtype
dtype('int32')
Save and Load data
X
array([[1, 2],
[3, 4]])
#파일 생성
np.save('my_array',X)
#파일 불러오기
Y = np.load('my_array.npy')
Y
array([[1, 2],
[3, 4]])
my_array.npy 파일이 폴더에 생겼는지 확인하세요.
BUILT-IN METHODS AND FUNCTIONS
# 3행 4열, 0으로 되어있는 행렬
np.zeros( (3,4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
# 0 7개 짜리 1차원 배열
np.zeros(7)
array([0., 0., 0., 0., 0., 0., 0.])
#1 5개 짜리 1차원 배열
np.ones(5)
array([1., 1., 1., 1., 1.])
# 2행 4열, 0으로 되어있는 행렬
np.ones((2,4))
array([[1., 1., 1., 1.],
[1., 1., 1., 1.]])
특정 값으로, 행렬 만들기
np.full(10, 5) #첫번쨰는 shape, 두번쨰는 채울 숫자
array([5, 5, 5, 5, 5, 5, 5, 5, 5, 5])
np.full((3,2), 5)
array([[5, 5],
[5, 5],
[5, 5]])
정수의 배열을 얻고자 할때
# 0부터 9까지 정수를 만드세요.
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range(10)
range(0, 10)
#넘파이에서는 range 개선한 함수 제공
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
range(4,9+1)
range(4, 10)
np.arange(4, 9+1)
array([4, 5, 6, 7, 8, 9])
np.arange(start,stop,step)
range(1,13+1,2)
range(1, 14, 2)
np.arange(1, 13+1, 2)
array([ 1, 3, 5, 7, 9, 11, 13])
정수 말고 실수를 얻고자 할때
np.linspace(0, 25, 10) # 첫번쨰는 시작, 두번쨰는 끝, 세번째는 갯수
array([ 0. , 2.77777778, 5.55555556, 8.33333333, 11.11111111,
13.88888889, 16.66666667, 19.44444444, 22.22222222, 25. ])
np.linspace(0, 25, 10, endpoint = False) # endpoint 파라미터 활용
array([ 0. , 2.5, 5. , 7.5, 10. , 12.5, 15. , 17.5, 20. , 22.5])
이렇게 1차원 배열을 얻은 후, 우리는 이것을 가지고 여러차원으로 만들 수 있다. reshape 을 이용
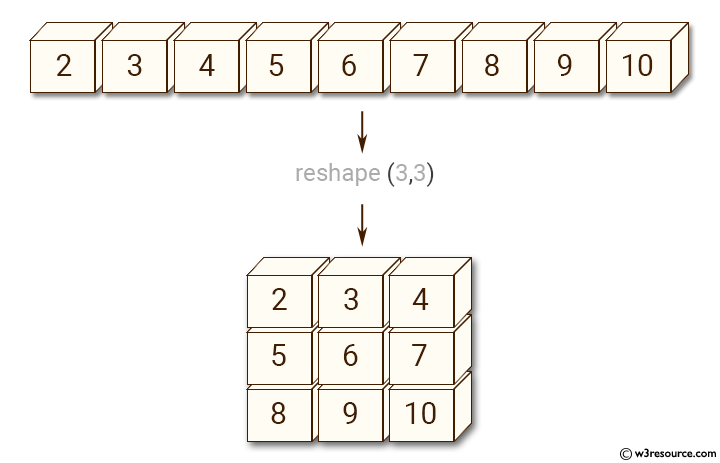
x = np.arange(20)
x
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
x.shape
(20,)
X = x.reshape(4,5)
X
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
X.reshape(2,10)
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])
X.shape # reshape는 메모리에 저장되지 않음
(4, 5)
y = X.reshape(20,1)
y.shape
(20, 1)
x.shape
(20,)
#x와 y는 다른 어레이. y는 2차원 배열이다.
X.ndim # ndim 속성은 몇차원 배열인지 나타낼수 있다.
2
x.ndim
1
y.ndim
2
여러단계를 거치지 말고, 한번에 원하는 다차원 배열로 만들 수 있다.
# 5 부터 시작해서 25개의 순차적인 정수를 만들고, 이를 5X5 행렬로 만든다.
x = np.arange(5,30)
X = x.reshape(5,5)
X
array([[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]])
np.arange(5, 30).reshape(5,5) #1줄로도 표현가능.
array([[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]])
랜덤값으로 채워진 배열을 만들 수 있다.
import random
random.random() # import random의 함수. 하나의 값만 가져옴
0.46407897695805767
np.random.random(8) # 넘파이의 랜덤 함수. 여러 값을 가져올수있음.
array([0.49679414, 0.85744989, 0.45252157, 0.5928989 , 0.88568985,
0.34210529, 0.79953484, 0.83333508])
np.random.random( (2,3) ) # 2차원 배열로도 가져올 수 있다.
array([[0.79672297, 0.5340739 , 0.35224309],
[0.7860801 , 0.69255879, 0.01927695]])
np.random.randint(start, stop, size = shape)
시작값과 끝값을 줄 수 있다.
np.random.randint(1,7, 10)
array([5, 5, 5, 5, 2, 2, 6, 2, 3, 3])
np.random.randint(1,7,(3,4))
array([[1, 5, 4, 4],
[5, 5, 4, 3],
[3, 2, 3, 6]])
정규분포를 만족하는 랜덤값으로 채우기
np.random.normal(mean, standard deviation, size=shape)
정규분포 (가우시안 분포)
- 대한민국 남자의 키 분포
- 수능 성적 분포
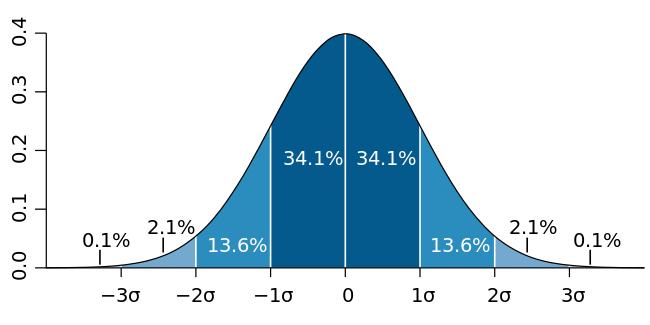
np.random.normal(170,10, (1000,1000))
array([[171.74563464, 168.65032264, 147.59531894, ..., 197.54557994,
165.70010392, 172.50617422],
[157.91360709, 164.14406459, 165.40943725, ..., 175.34133145,
176.09939889, 180.65524765],
[165.00257842, 166.17428001, 163.65963314, ..., 165.31274359,
173.12676402, 164.30649246],
...,
[176.48160234, 160.08945244, 163.8703577 , ..., 183.9927476 ,
176.80143206, 169.18052439],
[166.96530112, 163.98870914, 183.84877713, ..., 164.61766375,
187.63465248, 166.38477577],
[186.95571402, 159.43561988, 162.06171598, ..., 163.86890134,
170.01124457, 166.06635992]])
X = np.random.randint(1,100, (4,5))
X
array([[28, 14, 1, 19, 8],
[34, 70, 7, 7, 26],
[26, 14, 46, 66, 73],
[49, 80, 39, 92, 75]])
X.max() #최대 값
92
X.min() #최소 값
1
X.sum() #합
774
X.mean() #평균
38.7
X.std() #표준 편차
27.71840543754276
X
array([[28, 14, 1, 19, 8],
[34, 70, 7, 7, 26],
[26, 14, 46, 66, 73],
[49, 80, 39, 92, 75]])
# 각 행별 또는 엻별로 데이터를 분석할때는 축이 필요하다.
# 축 => axis 를 적어줘야 한다.
X.max(axis = 0)
array([49, 80, 46, 92, 75])
X.max(axis = 1)
array([28, 70, 73, 92])
# 각 행별 평균을 구하시오
X.mean(axis = 1)
array([14. , 28.8, 45. , 67. ])
X.sum(axis = 0)
array([137, 178, 93, 184, 182])
# X에 70보다 큰 데이터는 몇개가 있나요?
X > 70
array([[False, False, False, False, False],
[False, False, False, False, False],
[False, False, False, False, True],
[False, True, False, True, True]])
(X > 70).sum() # False = 0 , True = 1
4
# X의 데이터중 70보다 큰 데이터만 가져오시오.
X[X>70]
array([73, 80, 92, 75])
실습.
4 x 4 ndarray 만드세요.
단, 2 에서 32 까지의 순차적 짝수로 채워졌습니다.
X =
X = np.arange(2,33,2).reshape(4,4)
SHAPE, LENGTH AND TYPE OF NUMPY ARRAYS
X.dtype
dtype('int32')
X.size
16
MAX AND MIN VALUES AND THEIR INDEX
X.max()
32
X.min()
2
# 최대값이 어디에 있는지? 인덱스!
X.argmax()
15
# 최소값이 어디에 있는지?
X.argmin()
0
Accessing, Deleting, and Inserting Elements Into ndarrays
x = np.random.randint(1,20, 7)
x
array([14, 9, 13, 11, 16, 8, 3])
x[3]
11
x[-1]
3
다차원배열의 인덱스 접근
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
# 기존의 리스트에서 데이터 억세스하는 방식
X[1][1]
12
# 넘파이에서 추가된 방식
# 행 콤마 열로 사용
X[1,1]
12
항목 삭제
x
array([14, 9, 13, 11, 16, 8, 3])
np.delete(x,3)
array([14, 9, 13, 16, 8, 3])
x
array([14, 9, 13, 11, 16, 8, 3])
np.delete( x , [3,5] )
array([14, 9, 13, 16, 3])
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
# 행렬의 포맷이 깨지면서 1차원으로 나옴.
np.delete( X, 1)
array([ 2, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32])
np.delete(X,1,axis=0)
array([[ 2, 4, 6, 8],
[18, 20, 22, 24],
[26, 28, 30, 32]])
np.delete(X,3,axis=1)
array([[ 2, 4, 6],
[10, 12, 14],
[18, 20, 22],
[26, 28, 30]])
해당 요소만 딱 집어서 삭제
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
np.delete(X,[0,3],axis = 0)
array([[10, 12, 14, 16],
[18, 20, 22, 24]])
항목을 끝에 추가하기
x
array([14, 9, 13, 11, 16, 8, 3])
np.append(x,100)
array([ 14, 9, 13, 11, 16, 8, 3, 100])
np.append(x,[100,200,300])
array([ 14, 9, 13, 11, 16, 8, 3, 100, 200, 300])
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
a = np.arange(1,5)
a
array([1, 2, 3, 4])
a.shape
(4,)
A = a.reshape(1,4)
A
array([[1, 2, 3, 4]])
np.append(X , A , axis=0)
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32],
[ 1, 2, 3, 4]])
b = np.arange(4)
b
array([0, 1, 2, 3])
B = b.reshape(4,1)
B
array([[0],
[1],
[2],
[3]])
np.append(X,B,axis=1)
array([[ 2, 4, 6, 8, 0],
[10, 12, 14, 16, 1],
[18, 20, 22, 24, 2],
[26, 28, 30, 32, 3]])
항목을 원하는 위치에 추가하기
x
array([14, 9, 13, 11, 16, 8, 3])
np.insert(x,2,100) # 2번쨰 파라미터는 위치(인덱스), 세번째는 넣고싶은 데이터
array([ 14, 9, 100, 13, 11, 16, 8, 3])
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
a
array([1, 2, 3, 4])
np.insert(X, 2, A, axis=0)
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[ 1, 2, 3, 4],
[18, 20, 22, 24],
[26, 28, 30, 32]])
B
array([[0],
[1],
[2],
[3]])
np.insert(X,2,B,axis=1)
array([[ 2, 4, 0, 1, 2, 3, 6, 8],
[10, 12, 0, 1, 2, 3, 14, 16],
[18, 20, 0, 1, 2, 3, 22, 24],
[26, 28, 0, 1, 2, 3, 30, 32]])
b
array([0, 1, 2, 3])
np.insert(X,2,b,axis=1)
array([[ 2, 4, 0, 6, 8],
[10, 12, 1, 14, 16],
[18, 20, 2, 22, 24],
[26, 28, 3, 30, 32]])
Slicing - 잘라서 가져오기
- ndarray[start:end]
- ndarray[start:]
- ndarray[:end]
x
array([14, 9, 13, 11, 16, 8, 3])
# 기존 리스트 슬라이싱과 같음
x[0:4]
array([14, 9, 13, 11])
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
X[:3 ,:2 ]
array([[ 2, 4],
[10, 12],
[18, 20]])
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
X[1:,1:]
array([[12, 14, 16],
[20, 22, 24],
[28, 30, 32]])
# 두번쨰 행을 가져오세요.
X[1,]
array([10, 12, 14, 16])
# 세번쨰 컬럼을 가져오세요.
X[:,2]
array([ 6, 14, 22, 30])
# 첫번째 컬럼과 네번째 컬럼만 가져오세요
X[:,[0,3]]
array([[ 2, 8],
[10, 16],
[18, 24],
[26, 32]])
Slicing 할때, 주의할 점!!!!
X
array([[ 2, 4, 6, 8],
[10, 12, 14, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
X[1,2]= 100
X
array([[ 2, 4, 6, 8],
[ 10, 12, 100, 16],
[ 18, 20, 22, 24],
[ 26, 28, 30, 32]])
Z = X[:3,2:]
Z
array([[ 6, 8],
[100, 16],
[ 22, 24]])
Z[1,0] = 0
Z
array([[ 6, 8],
[ 0, 16],
[22, 24]])
X
array([[ 2, 4, 6, 8],
[10, 12, 0, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
# 그냥 슬라이싱해서 Z변수에 담아서 처리하면,
# 원본 X를 공유하게 되므로,
# Z 변수를 통해서 변경한 데이터가 X에도 똑같이 변경된다.
# 따라서 복사해서 사용하는 방법이 있다.
Copy - 2가지 방법
Z = np.copy(X[:3,2:])
Z[0,0] = 10000
Z
array([[10000, 8],
[ 0, 16],
[ 22, 24]])
X
array([[ 2, 4, 6, 8],
[10, 12, 0, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
# 2번쨰 방법
Z = X[:3,2:].copy()
Z[0,0] = 10000
X
array([[ 2, 4, 6, 8],
[10, 12, 0, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
Z
array([[10000, 8],
[ 0, 16],
[ 22, 24]])
중복된것 제거한 값만 리스트로 가져오기
x = np.random.randint(1, 5,10)
x
array([4, 3, 2, 2, 4, 1, 2, 3, 4, 3])
np.unique(x)
array([1, 2, 3, 4])
boolean 연산
X
array([[ 2, 4, 6, 8],
[10, 12, 0, 16],
[18, 20, 22, 24],
[26, 28, 30, 32]])
(X > 16).sum()
8
# X가 16보다 큰 데이터를 가져오시오
X > 16
array([[False, False, False, False],
[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]])
X[X>16]
array([18, 20, 22, 24, 26, 28, 30, 32])
# X의 데이터중에서, 10보다 크고 30보다 작은 데이터만 가져오시오.
# 데이터 억세스에서는, 그리고가 and가 아니라, &로 사용!
(X > 10) & (X<30)
array([[False, False, False, False],
[False, True, False, True],
[ True, True, True, True],
[ True, True, False, False]])
X[(X > 10) & (X < 30)]
array([12, 16, 18, 20, 22, 24, 26, 28])
#X 가 10보다 작거나 20보다 큰 데이터만 가져오시오
# or 연산자가 아니라 | 연산자를 사용해서 ,또는 을 처리한다.
X[(X < 10) | (X > 20)]
array([ 2, 4, 6, 8, 0, 22, 24, 26, 28, 30, 32])
실습 X = 5 x 5 ndarray 를 만드세요.정수 1 부터 25 까지 순차적으로 들어있습니다. Y = Boolean indexing 을 이용해서 홀수만 뽑아서 배열로 만듭니다.
X = np.arange(1,26).reshape(5,5)
X
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
Y = X[X % 2 == 1]
Y
array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25])
Arithmetic operations and Broadcasting
1차원 배열 연산
x = np.random.randint(1,10,4)
y = np.random.randint(10,100,4)
y
array([39, 80, 71, 24])
x
array([7, 5, 9, 8])
a = [1,3,4]
b = [6,7,8]
a + b
[1, 3, 4, 6, 7, 8]
x + y
array([46, 85, 80, 32])
x - y
array([-32, -75, -62, -16])
x * y
array([273, 400, 639, 192])
x / y
array([0.17948718, 0.0625 , 0.12676056, 0.33333333])
2차원 배열 연산
X = np.arange(1,5).reshape(2,2)
Y = np.random.randint(10, 20 ,(2,2))
X
array([[1, 2],
[3, 4]])
Y
array([[11, 14],
[14, 11]])
X - Y
array([[-10, -12],
[-11, -7]])
X + Y
array([[12, 16],
[17, 15]])
X * Y
array([[11, 28],
[42, 44]])
X / Y
array([[0.09090909, 0.14285714],
[0.21428571, 0.36363636]])
각 요소마다 연산이 수행됨, 브로드캐스팅
score_list = [90,97,35,67,88,24,69]
new_list =[i + 3 for i in score_list]
new_list
[93, 100, 38, 70, 91, 27, 72]
# 리스트를 넘파이로 만들고
score_array = np.array(score_list)
# 그냥 더하면 끝
score_array + 3
array([ 93, 100, 38, 70, 91, 27, 72])
실습 위의 Broadcasting을 이용하여, 다음과 같은 4 x 4 ndarray를 만듭니다. [[1. 2. 3. 4.]
[1. 2. 3. 4.]
[1. 2. 3. 4.]
[1. 2. 3. 4.]]
X =
X = np.ones((4,4))
np.arange(4)
array([0, 1, 2, 3])
X + np.arange(4)
array([[1., 2., 3., 4.],
[1., 2., 3., 4.],
[1., 2., 3., 4.],
[1., 2., 3., 4.]])
댓글남기기