머신러닝 - Multiple_Linear
Multiple Linear Regression
아래처럼, 여러개의 features 를 기반으로, 수익을 예측하려 한다.
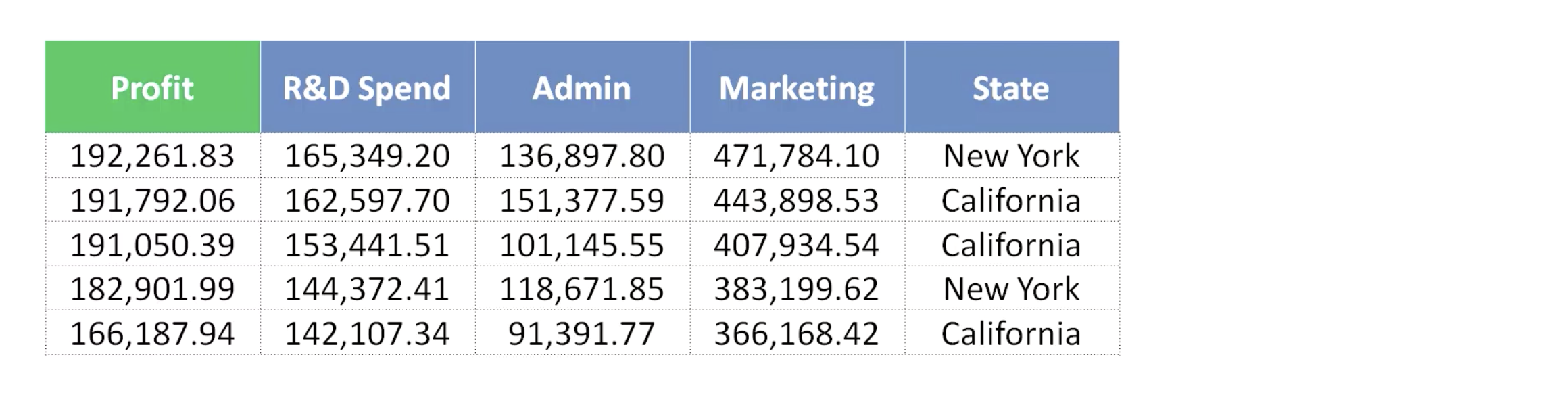 위와 같이, 여러개의 변수들을 통해, 수익과의 관계를 분석하고,
위와 같이, 여러개의 변수들을 통해, 수익과의 관계를 분석하고,
이를 통해, 새로운 데이터가 들어왔을 때, 수익이 어떻게 될 지를 예측하고자 한다.
아래는 하나의 변수일때와, 여러개의 변수가 있을때의 leaner regression 을 나타낸다.
2차원에서는 선 이지만, 3차원에서는 평면이 된다.
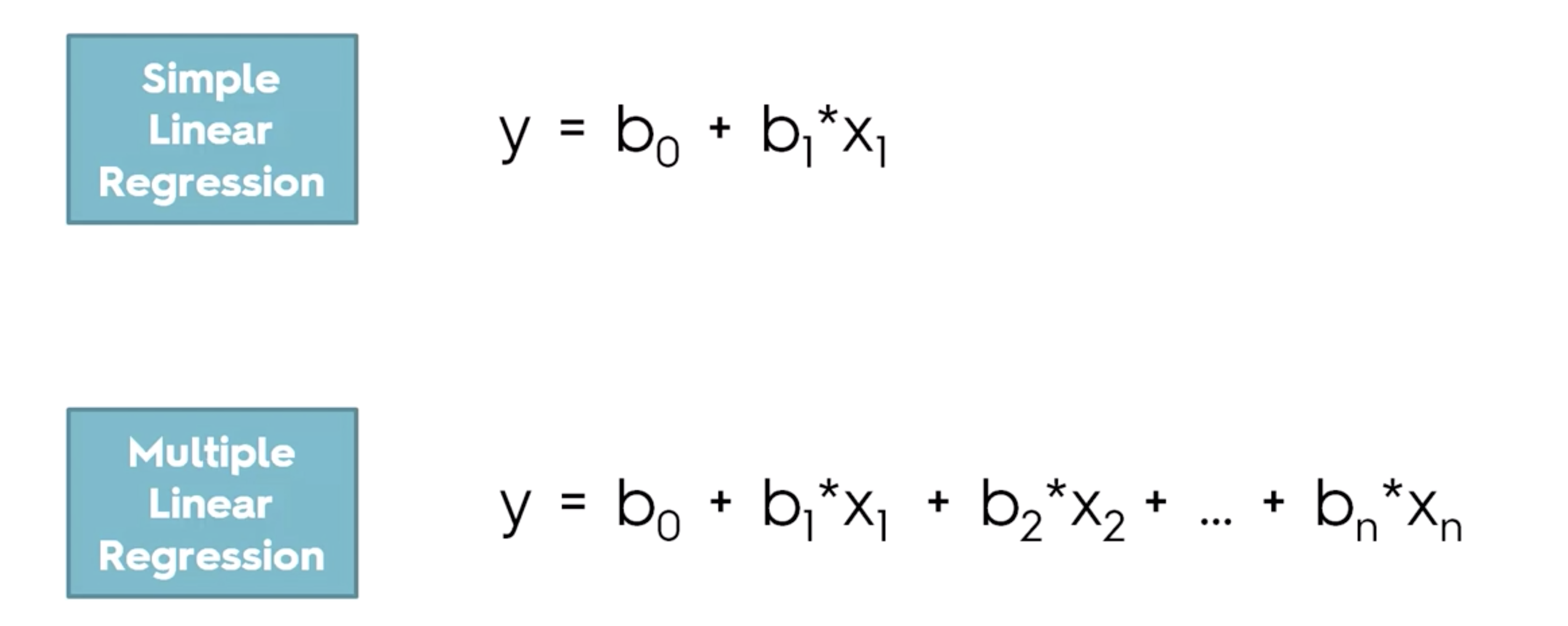
오차가 가장 적을때의 b 값들을 찾아보자.
# Profit 수익을 예측하려 한다. 이것이 디펜더블 베리어블, 나머지는 인디펜더블 베리어블
Multiple Linear Regression 모델링 순서
1. 먼저 식을 세운다.숫자가 아닌값의 처리.
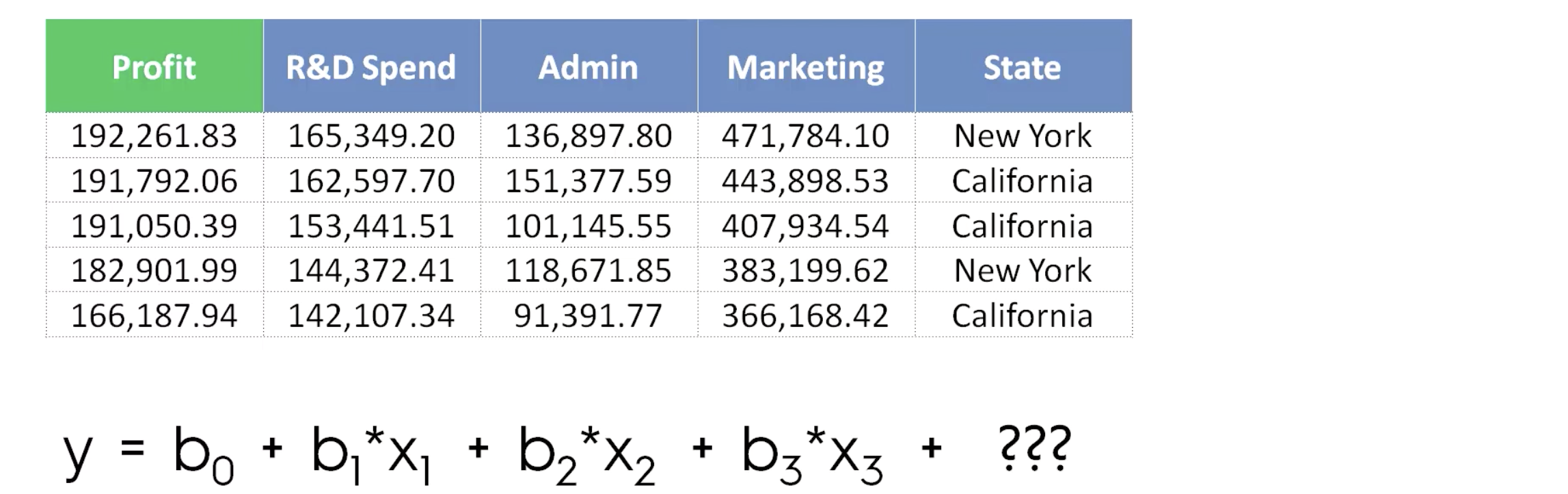 catergorical 로 바꿔주면 된다.
catergorical 로 바꿔주면 된다.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
각각의 피쳐를 분석하여, 어떤 신생 회사의 데이터가 있으면, 그 회사가 얼마의 수익을 낼 지 예측합니다. (투자를 해야 할지 말아야 할지)
df=pd.read_csv('50_Startups.csv')
df.head()
| R&D Spend | Administration | Marketing Spend | State | Profit | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | New York | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | California | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 |
| 3 | 144372.41 | 118671.85 | 383199.62 | New York | 182901.99 |
| 4 | 142107.34 | 91391.77 | 366168.42 | Florida | 166187.94 |
2. 데이터 분석
# Nan 확인
df.isna().sum()
R&D Spend 0
Administration 0
Marketing Spend 0
State 0
Profit 0
dtype: int64
3. 데이터 가공
# 어떤 인공지능을 개발할지 X, y 값을 세팅해준다.
df.head(3)
| R&D Spend | Administration | Marketing Spend | State | Profit | |
|---|---|---|---|---|---|
| 0 | 165349.20 | 136897.80 | 471784.10 | New York | 192261.83 |
| 1 | 162597.70 | 151377.59 | 443898.53 | California | 191792.06 |
| 2 | 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 |
X = df.iloc[:,:4]
y = df['Profit']
3-1 문자열 인코딩
# 문자열이 들어있는 컬럼이 있다.
# 따라서, 문자열 컬럼은 숫자로 바꿔줘야 한다.
# 문자열 컬럼이 카테고리컬 데이터인지 먼저 확인
X['State'].describe()
count 50
unique 3
top New York
freq 17
Name: State, dtype: object
# 알파벳순으로 정렬
sorted(X['State'].unique())
['California', 'Florida', 'New York']
# 카테고리컬 데이터가 3개 이상 이므로 원핫 인코딩을 한다.
# 'Caolifornia' 'Folrida' 'New York'
# 0 0 1
# 1 0 0
# 0 1 0
X = pd.get_dummies(X,columns=['State'])
4. 인공지능 학습
# 모두 숫자로 변경되었으니,
# train / test 용 데이터로 분리한다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size= 0.2,random_state = 21)
# 인공지능 모델링!
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train,y_train)
LinearRegression()
5. 인공지능 테스트
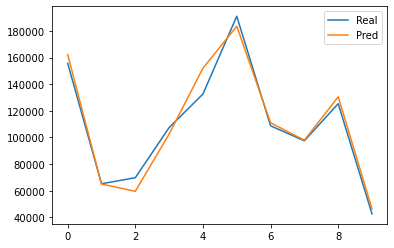
y_pred = regressor.predict(X_test)
error = y_test - y_pred
# MSE 구하기
(error**2).mean()
64977449.20857227
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real','Pred'])
plt.show()
댓글남기기