머신러닝 - Logistic-Regression
Logistic Regression
분류에 사용한다. (Classification)
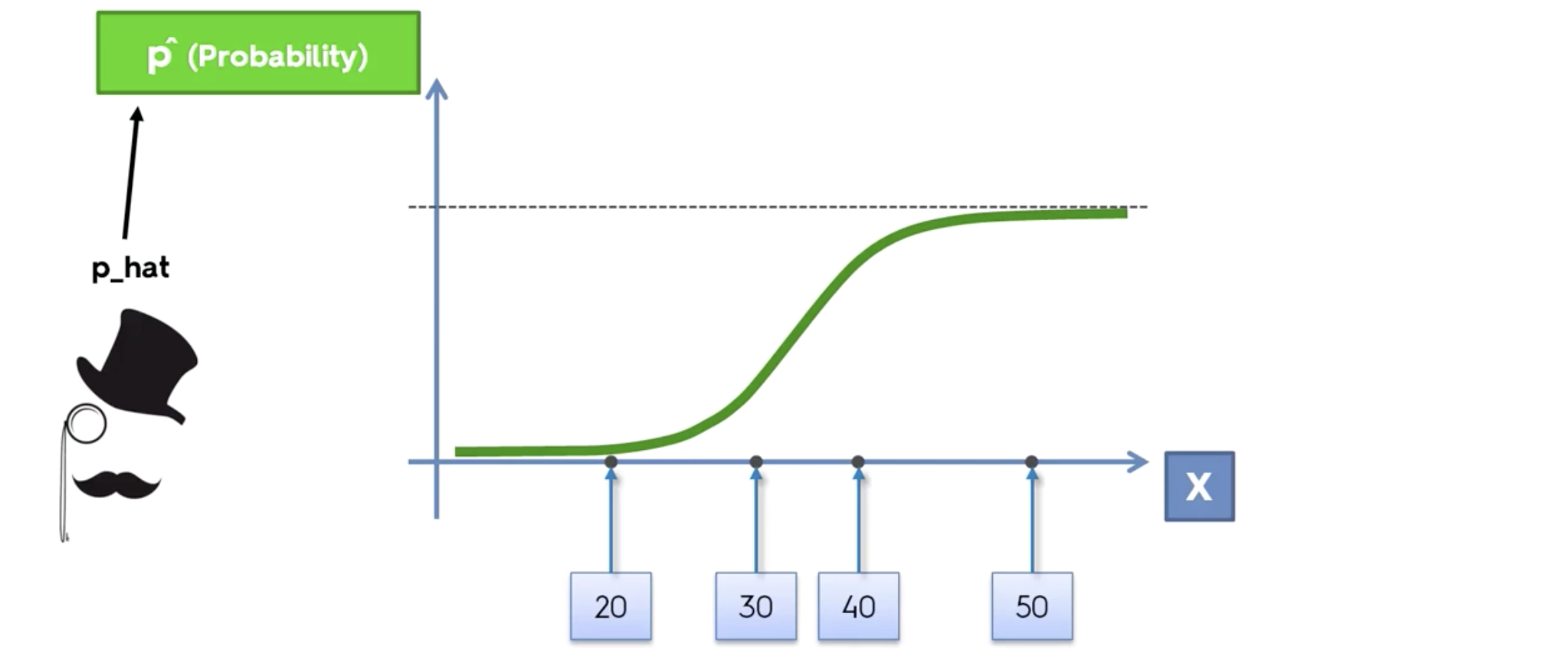
예) 나이대별로 이메일을 클릭해서 열지 말지를 분류해 보자.
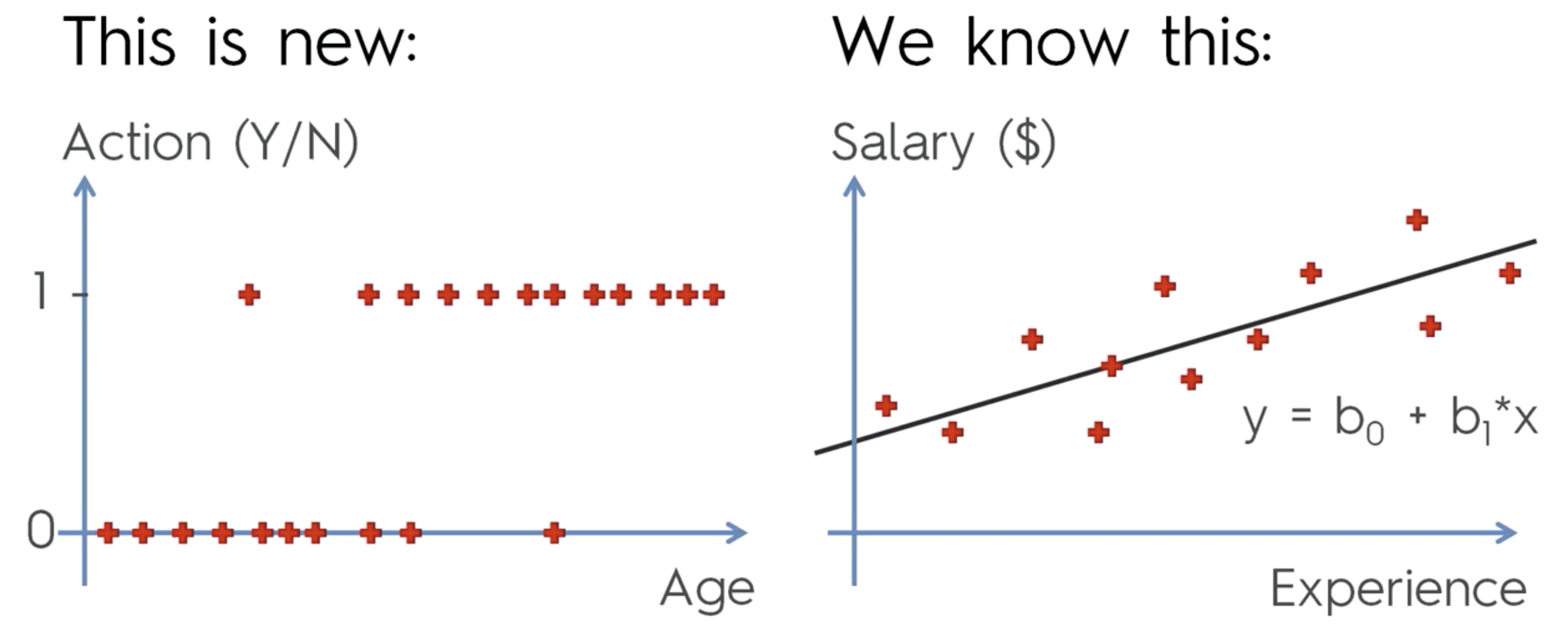
이메일 클릭을 할 사람과 안할 사람으로 분류할 것이다.
빨간점이 바로 데이터이며,
액션의 0 과 1 이 바로 레이블이다.
레이블이 있다는것은, 수퍼바이저드 러닝 이라는 뜻
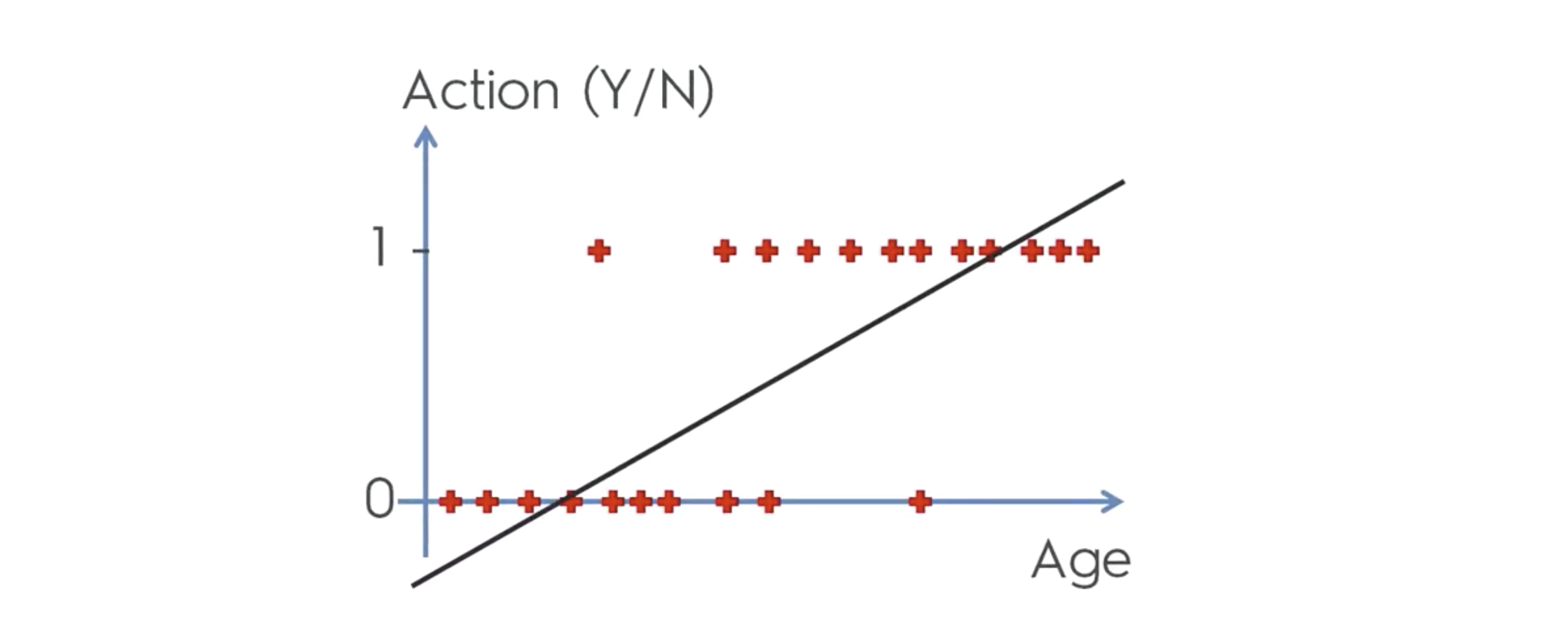
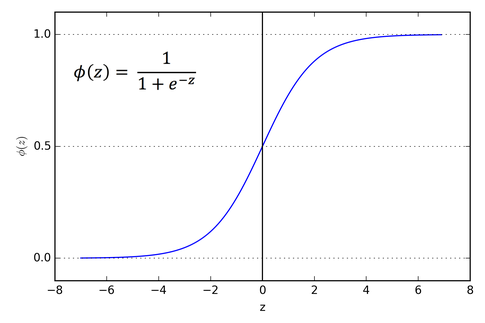
 이렇게 비슷하게 생긴 함수가 이미존재한다. 이름은 sigmoid function
이렇게 비슷하게 생긴 함수가 이미존재한다. 이름은 sigmoid function
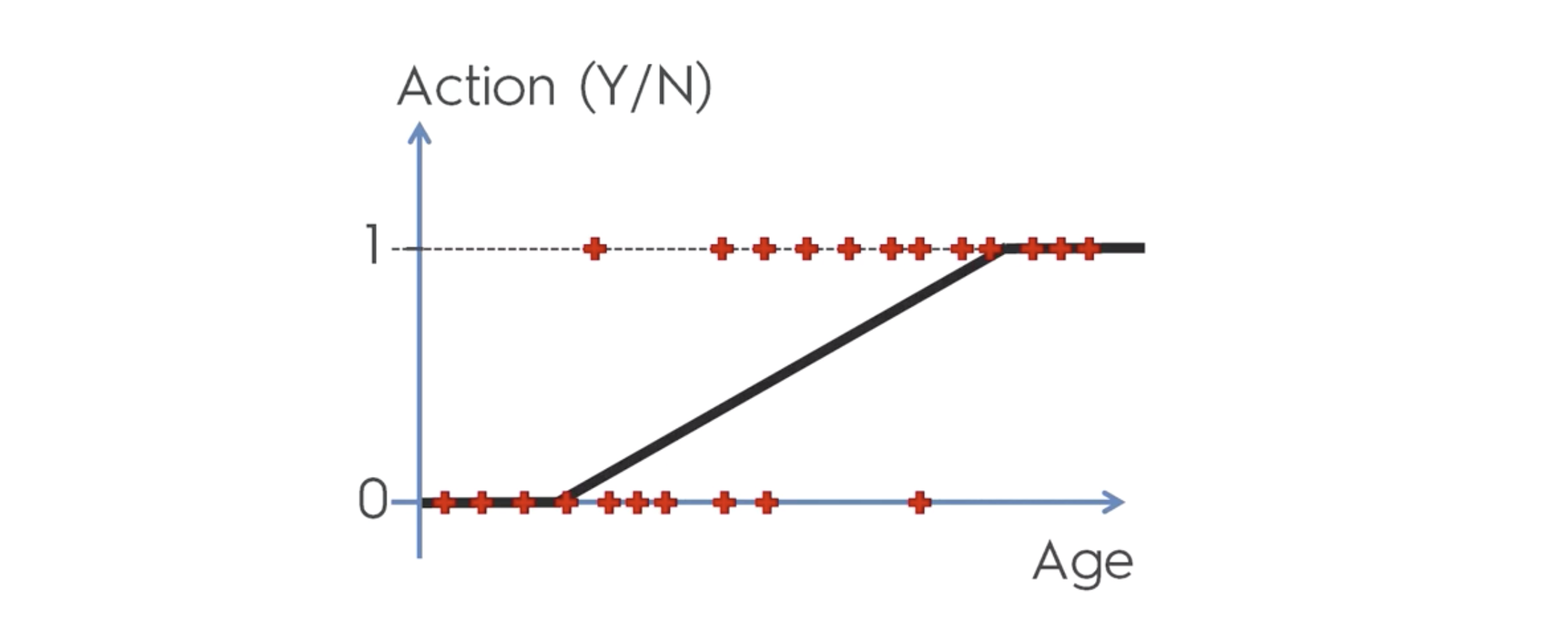
따라서 리니어 리그레션 식을, y 값을 시그모이드에 대입해서, 일차방정식으로 만들면 다음과 같아진다.
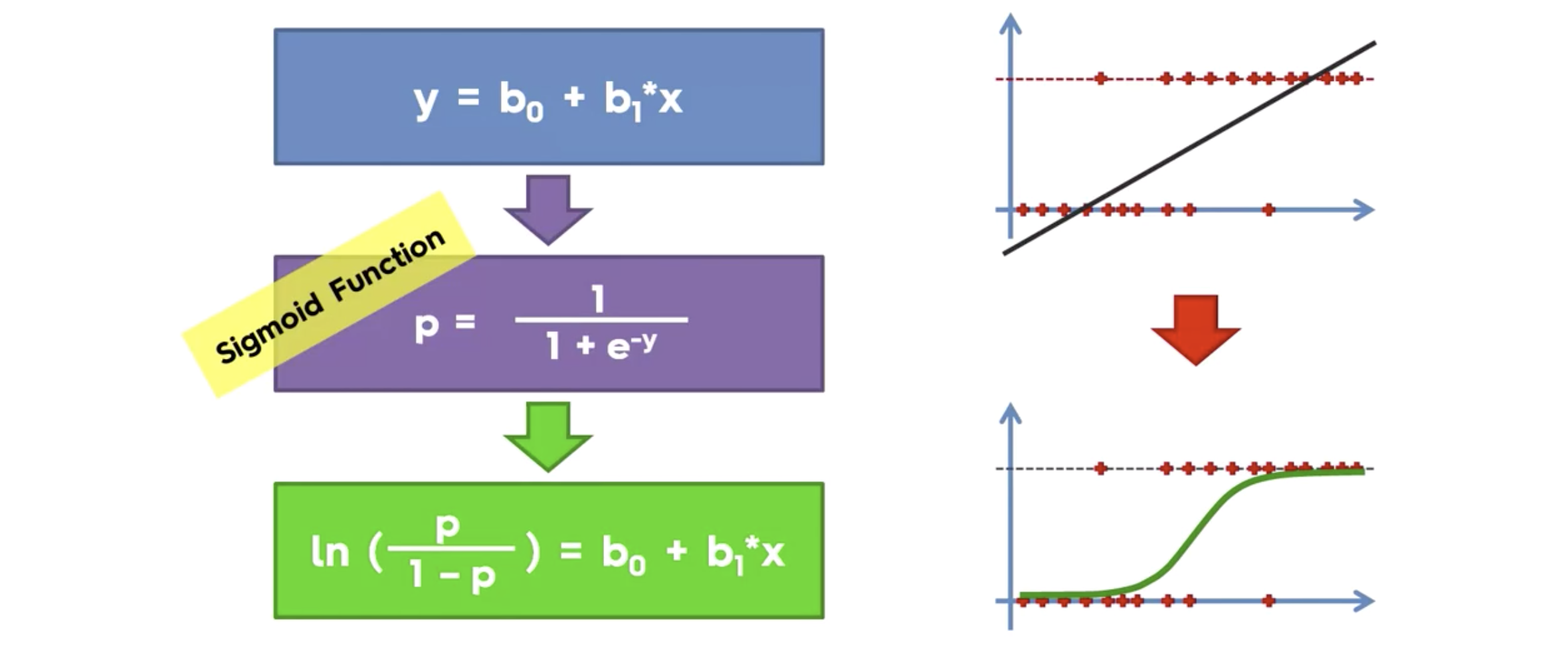 위와 같은 식을 가진 regression 을, Logistic Regression이라 한다.
위와 같은 식을 가진 regression 을, Logistic Regression이라 한다.
이제 우리는, 이를 가지고 두개의 클래스로 분류할 수 있다. ( 클릭을 한다, 안한다 두개로.)
확률로 나타낼 수 있게 되었다.
p는 확률값을 나타낸다.
20대는 클릭할 확률이 0.7%, 40대는 85%, 50대는 99.4%
이 확률값은, 위에서의 시그모이드 함수를 적용한 식을 통해 나온 값임을 기억한다.
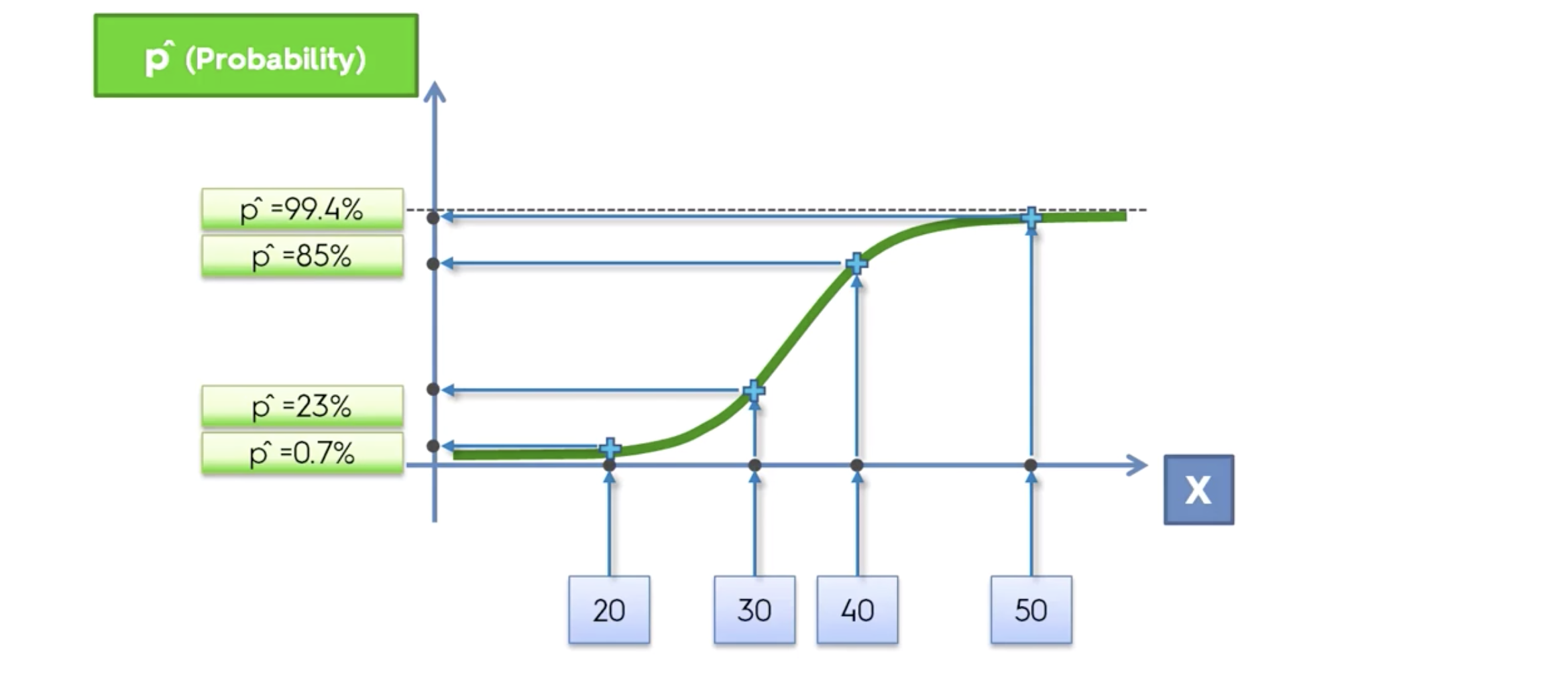
최종 예측값은, 0.5를 기준으로 두개의 부류로 나눈다. 그 값은 0 과 1 이다.

모델링 순서
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 나이와 연봉으로 분석해서, 물건을 구매할지 안할지를 분류하자!!
df = pd.read_csv('Social_Network_Ads.csv')
df
| User ID | Gender | Age | EstimatedSalary | Purchased | |
|---|---|---|---|---|---|
| 0 | 15624510 | Male | 19 | 19000 | 0 |
| 1 | 15810944 | Male | 35 | 20000 | 0 |
| 2 | 15668575 | Female | 26 | 43000 | 0 |
| 3 | 15603246 | Female | 27 | 57000 | 0 |
| 4 | 15804002 | Male | 19 | 76000 | 0 |
| ... | ... | ... | ... | ... | ... |
| 395 | 15691863 | Female | 46 | 41000 | 1 |
| 396 | 15706071 | Male | 51 | 23000 | 1 |
| 397 | 15654296 | Female | 50 | 20000 | 1 |
| 398 | 15755018 | Male | 36 | 33000 | 0 |
| 399 | 15594041 | Female | 49 | 36000 | 1 |
400 rows × 5 columns
1. 데이터 분석
df.isna().sum()
User ID 0
Gender 0
Age 0
EstimatedSalary 0
Purchased 0
dtype: int64
X = df.iloc[:,[2,3]]
y = df['Purchased']
2. 데이터 가공
# 로지스틱 리그레션은, 피쳐스케일링을 한다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
3. 인공지능 학습
# Train / Test 용 데이터 생성
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2,random_state= 10)
# 모델링, 분류의 문제이므로 분류의 문제를 해결할수 있는 인공지능으로 모델링한다.
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state=10)
classifier.fit(X_train,y_train)
LogisticRegression(random_state=10)
4. 인공지능 테스트
# 성능평가
y_pred = classifier.predict(X_test)
y_pred
array([0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0,
0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1,
0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0], dtype=int64)
Confusion Matrix
 )
)
두 개의 클래스로 분류하는 경우는 아래와 같다.

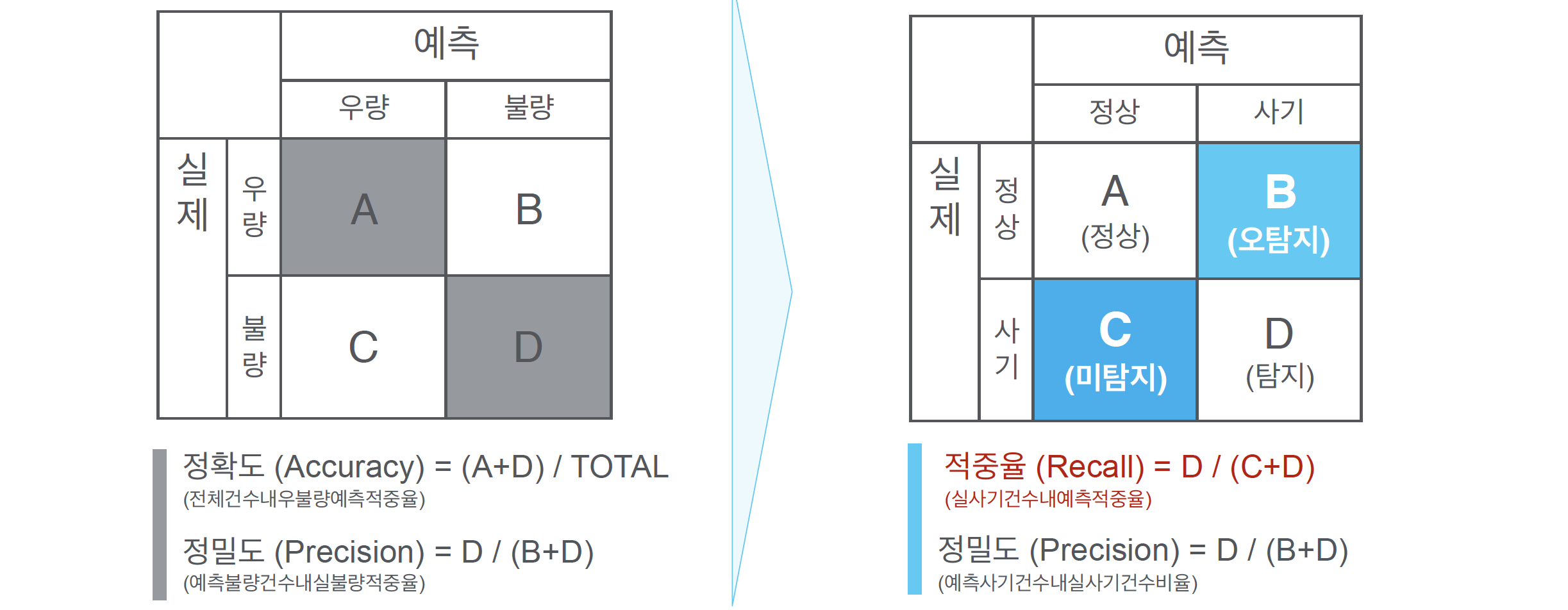
confusion_matrix를 이용하여 테스트 결과 분석
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
cm
array([[48, 4],
[ 5, 23]], dtype=int64)
# 정확도 accuracy 계산
# 맞춘것의 갯수 / 전체 갯수
(48+23) / cm.sum()
0.8875
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_pred)
0.8875
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
precision recall f1-score support
0 0.91 0.92 0.91 52
1 0.85 0.82 0.84 28
accuracy 0.89 80
macro avg 0.88 0.87 0.88 80
weighted avg 0.89 0.89 0.89 80



테스트 데이터와 트레이닝 데이터 시각화
# 테스트 데이터 시각화
# Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
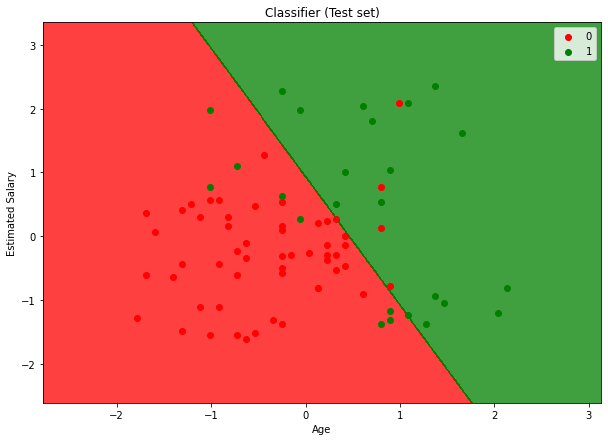
학습에 사용된 데이터를 시각화
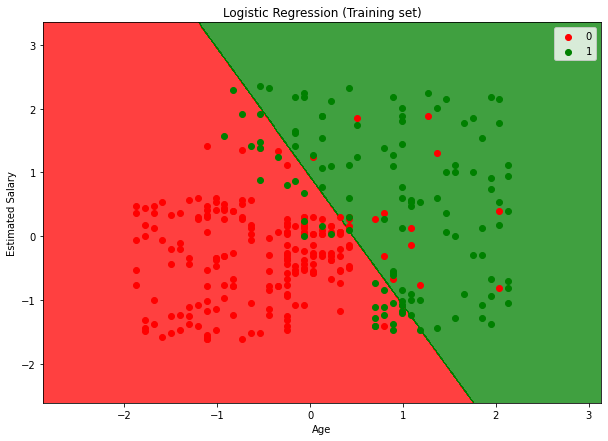
# Visualising the Training set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Logistic Regression (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
댓글남기기